
大家好,我是考100分的小小码 ,祝大家学习进步,加薪顺利呀。今天说一说What's New in DataGrip 2021.3,希望您对编程的造诣更进一步.
What's New in DataGrip 2021.3
What's New in DataGrip 2021.3
DataGrip 2021.3 is here! This is the third major update of 2021, and it’s packed with various
enhancements. Let’s take a look at what it has to offer!
Data editor
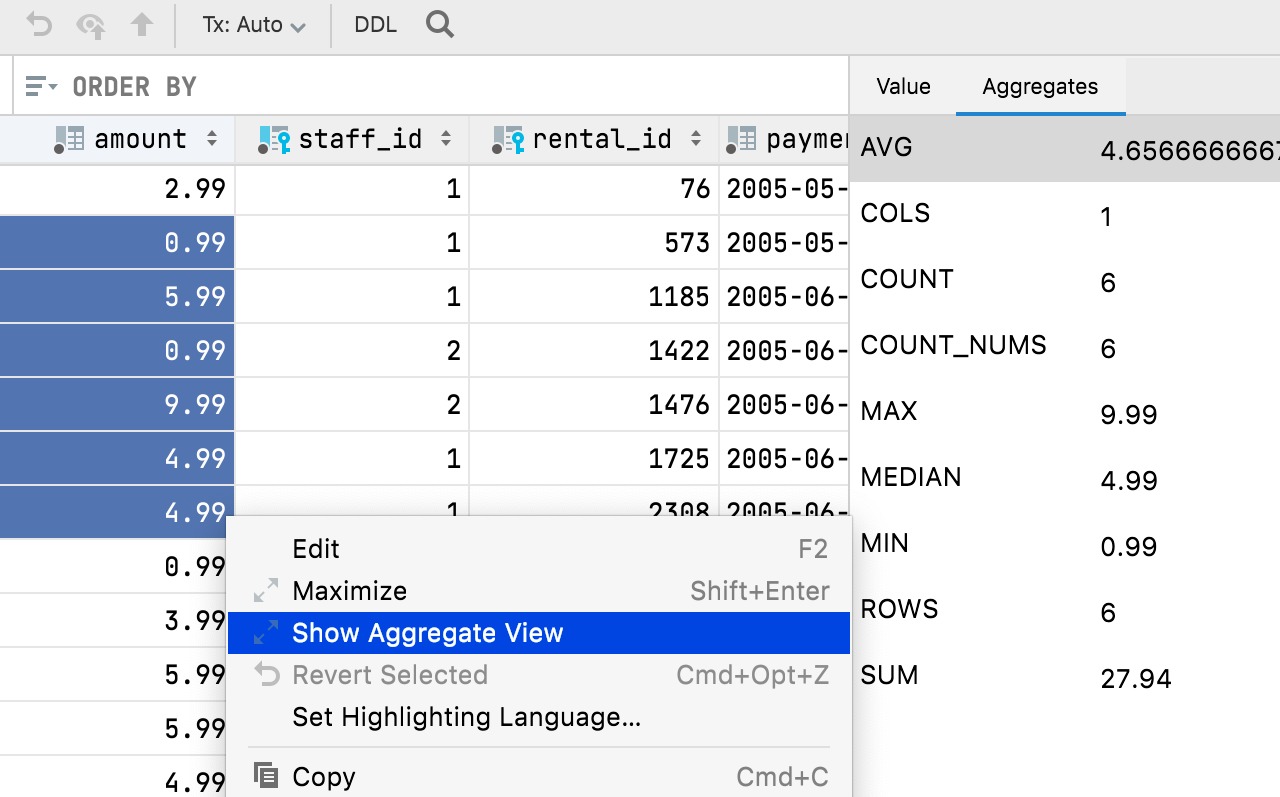 Aggregates We’ve added the ability to display an Aggregate view for a range of cells. This is a long-awaited feature that will help you manage your data and spare you from having to write additional queries! This makes the data editor more powerful and easier to use, bringing it a step closer to Excel and Google Spreadsheets. Select the cell range you want to see the view for, then right click and select Show Aggregate View.
Aggregates We’ve added the ability to display an Aggregate view for a range of cells. This is a long-awaited feature that will help you manage your data and spare you from having to write additional queries! This makes the data editor more powerful and easier to use, bringing it a step closer to Excel and Google Spreadsheets. Select the cell range you want to see the view for, then right click and select Show Aggregate View.
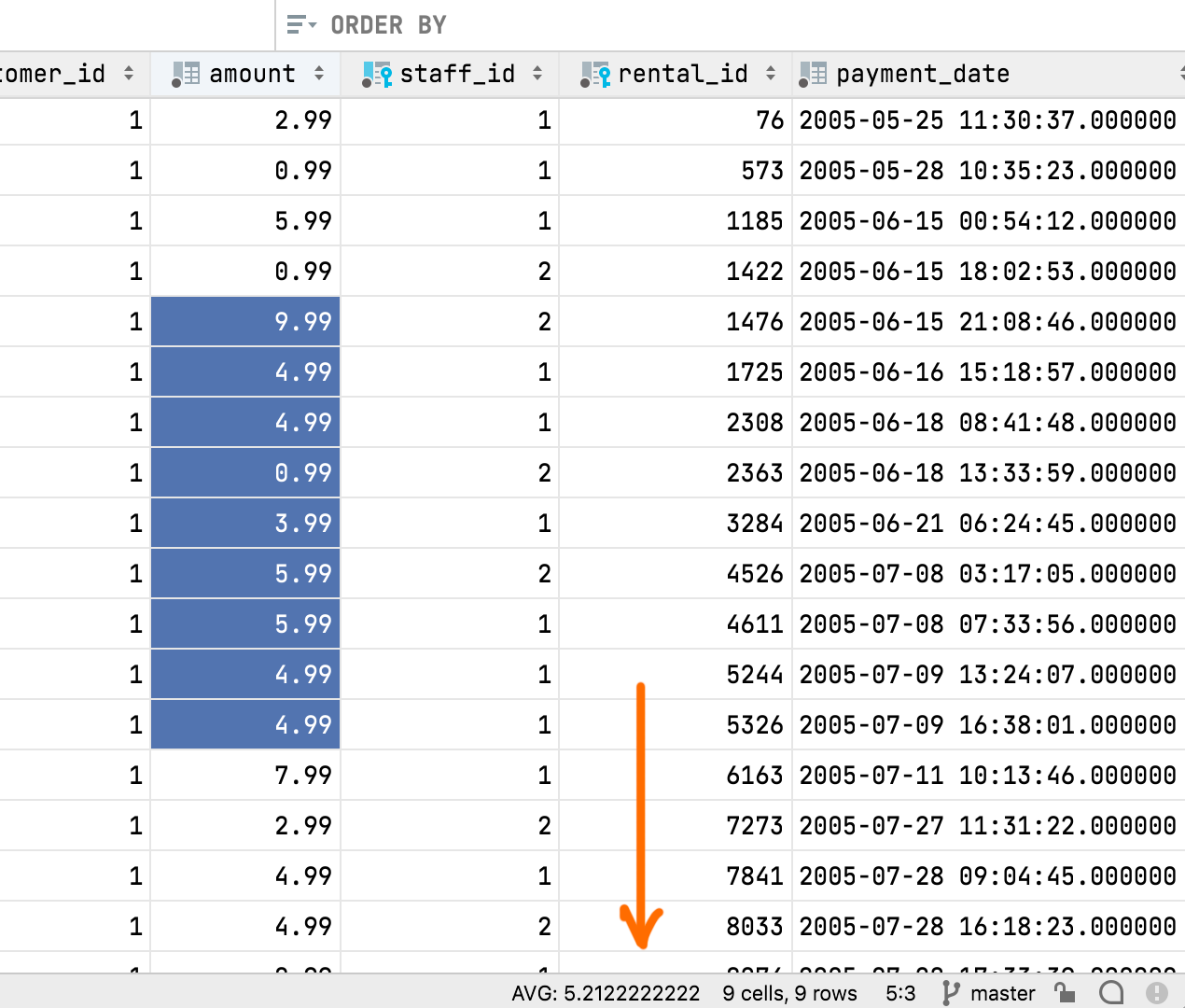 Quick facts: The Aggregate view shares the panel with Value view, each with its own tab now. You can move this panel to the bottom of the data editor. You can use the gear icon to display or hide any aggregate from this view. Like extractors, aggregates are scripts. You can create and share your own in addition to the nine scripts we’ve bundled by default. Aggregate scripts and extractors are interchangeable. If you’ve previously used an extractor to get just one value, you can now copy it to the Aggregators folder and use it for aggregates. Like the Extractors folder, it is located in Scratches and consoles / Extensions / Database Tools and SQL. One aggregate value is displayed in the status bar, and you can choose which value (sum, mean, median, min, max, and so on) you’d like it to be.
Quick facts: The Aggregate view shares the panel with Value view, each with its own tab now. You can move this panel to the bottom of the data editor. You can use the gear icon to display or hide any aggregate from this view. Like extractors, aggregates are scripts. You can create and share your own in addition to the nine scripts we’ve bundled by default. Aggregate scripts and extractors are interchangeable. If you’ve previously used an extractor to get just one value, you can now copy it to the Aggregators folder and use it for aggregates. Like the Extractors folder, it is located in Scratches and consoles / Extensions / Database Tools and SQL. One aggregate value is displayed in the status bar, and you can choose which value (sum, mean, median, min, max, and so on) you’d like it to be.
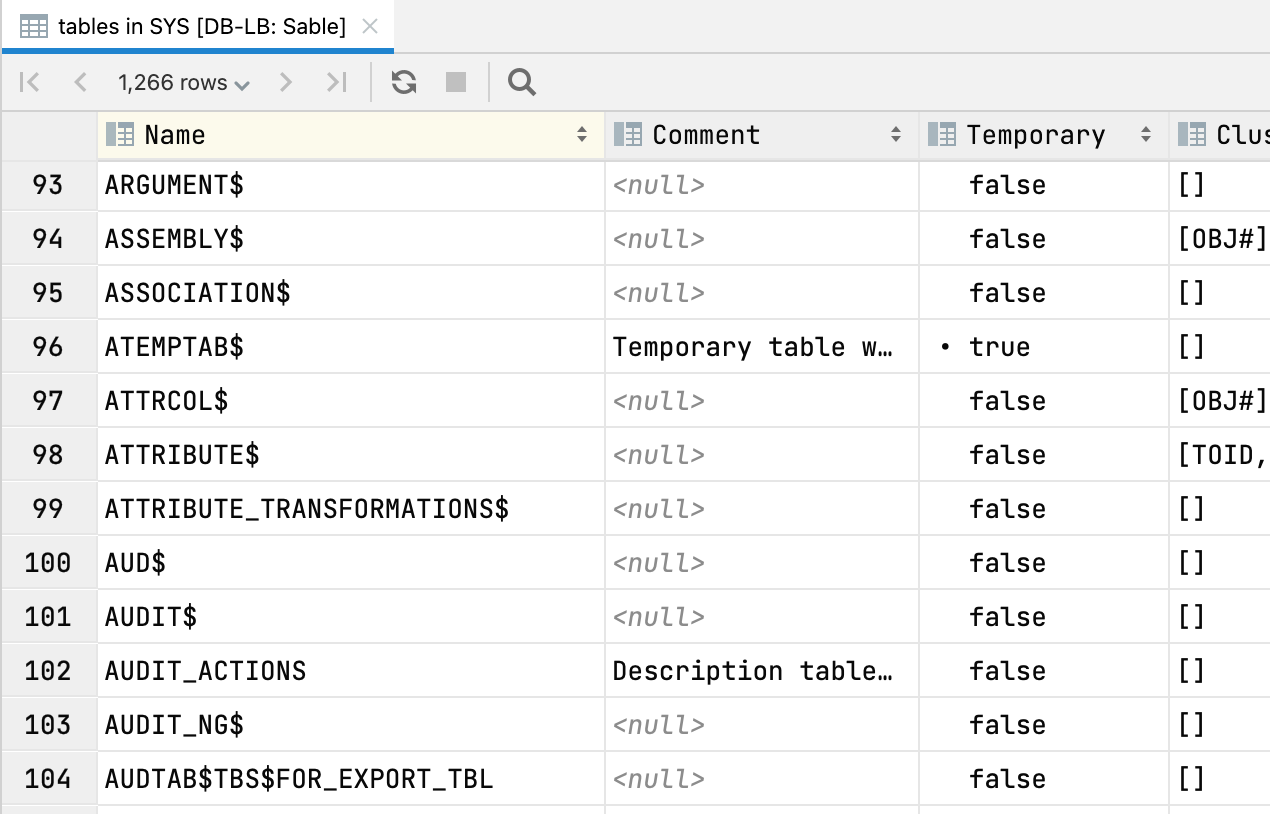 Table view for tree nodes Pressing F4 on any schema node displays a table view of the node’s contents. For example, you can get a table view of all tables in your schema:
Table view for tree nodes Pressing F4 on any schema node displays a table view of the node’s contents. For example, you can get a table view of all tables in your schema:
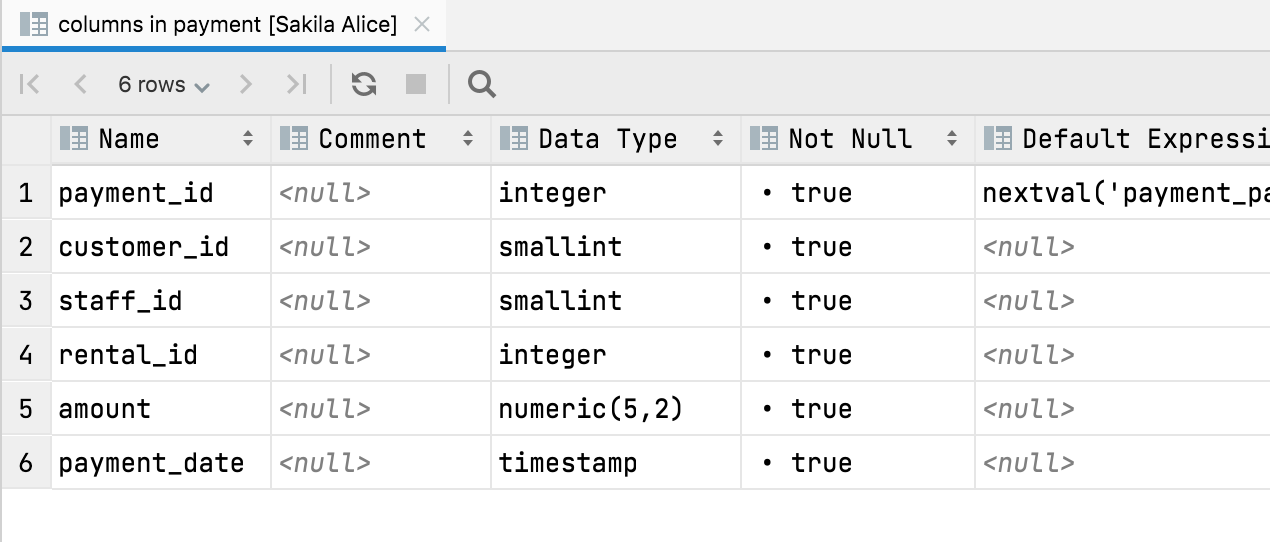 Or you can view a table view of a table’s columns: You can use this view to hide/show columns, export the data to many formats, and use text search. More importantly, the following navigation actions work here, too: Ctrl+B shows you the DDL. F4 shows the data. Alt+Shift+B highlights the object in the database tree.
Or you can view a table view of a table’s columns: You can use this view to hide/show columns, export the data to many formats, and use text search. More importantly, the following navigation actions work here, too: Ctrl+B shows you the DDL. F4 shows the data. Alt+Shift+B highlights the object in the database tree.
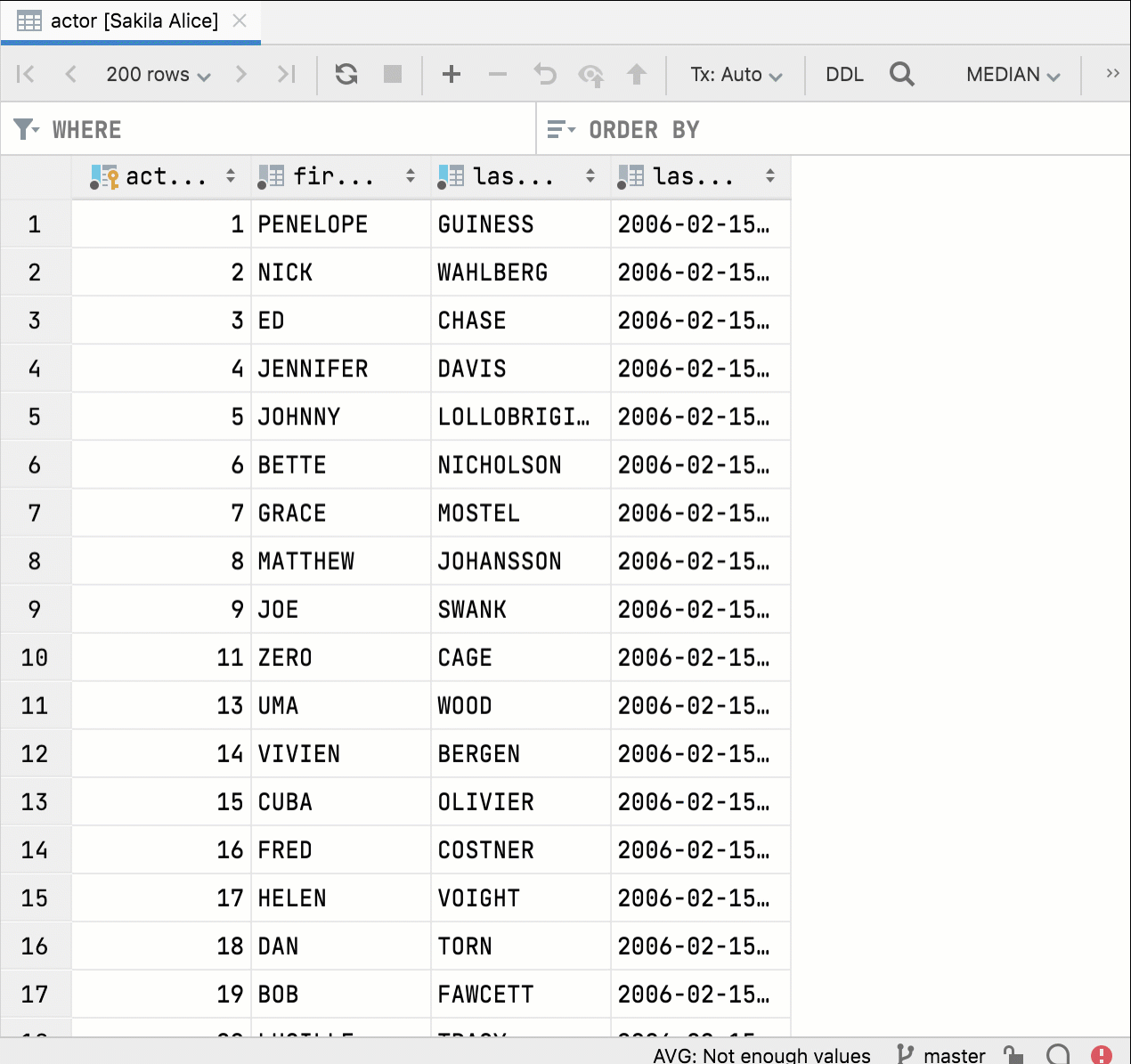 Independent split If you split the editor and open the same table again, the two data editor windows will now be completely independent. You can then set different filtering and ordering options for them to compare and work with the data. Previously, filtering and ordering were synchronized, which was less than ideal.
Independent split If you split the editor and open the same table again, the two data editor windows will now be completely independent. You can then set different filtering and ordering options for them to compare and work with the data. Previously, filtering and ordering were synchronized, which was less than ideal.
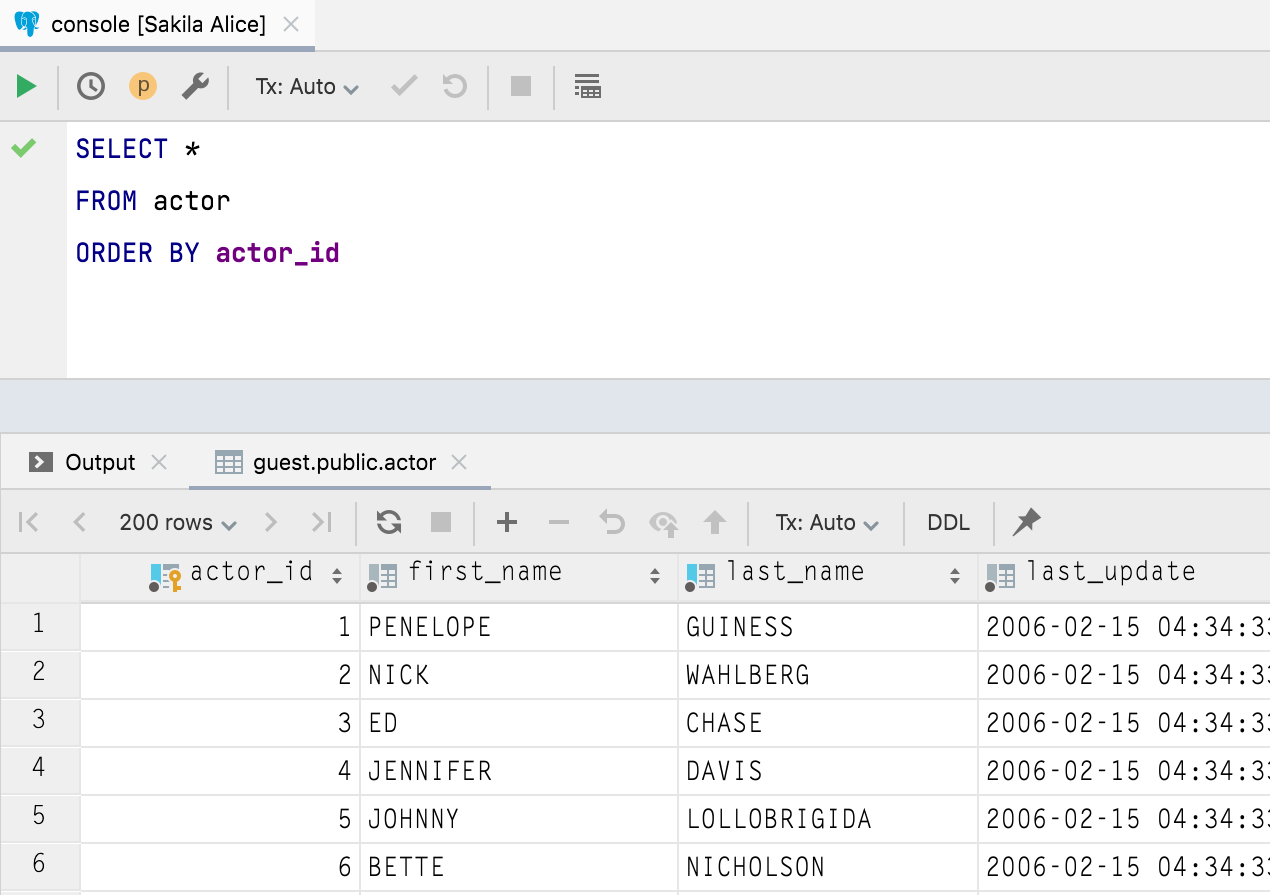 Custom font You can choose a dedicated font for displaying data under Database | Data views | Use custom font.
Custom font You can choose a dedicated font for displaying data under Database | Data views | Use custom font.
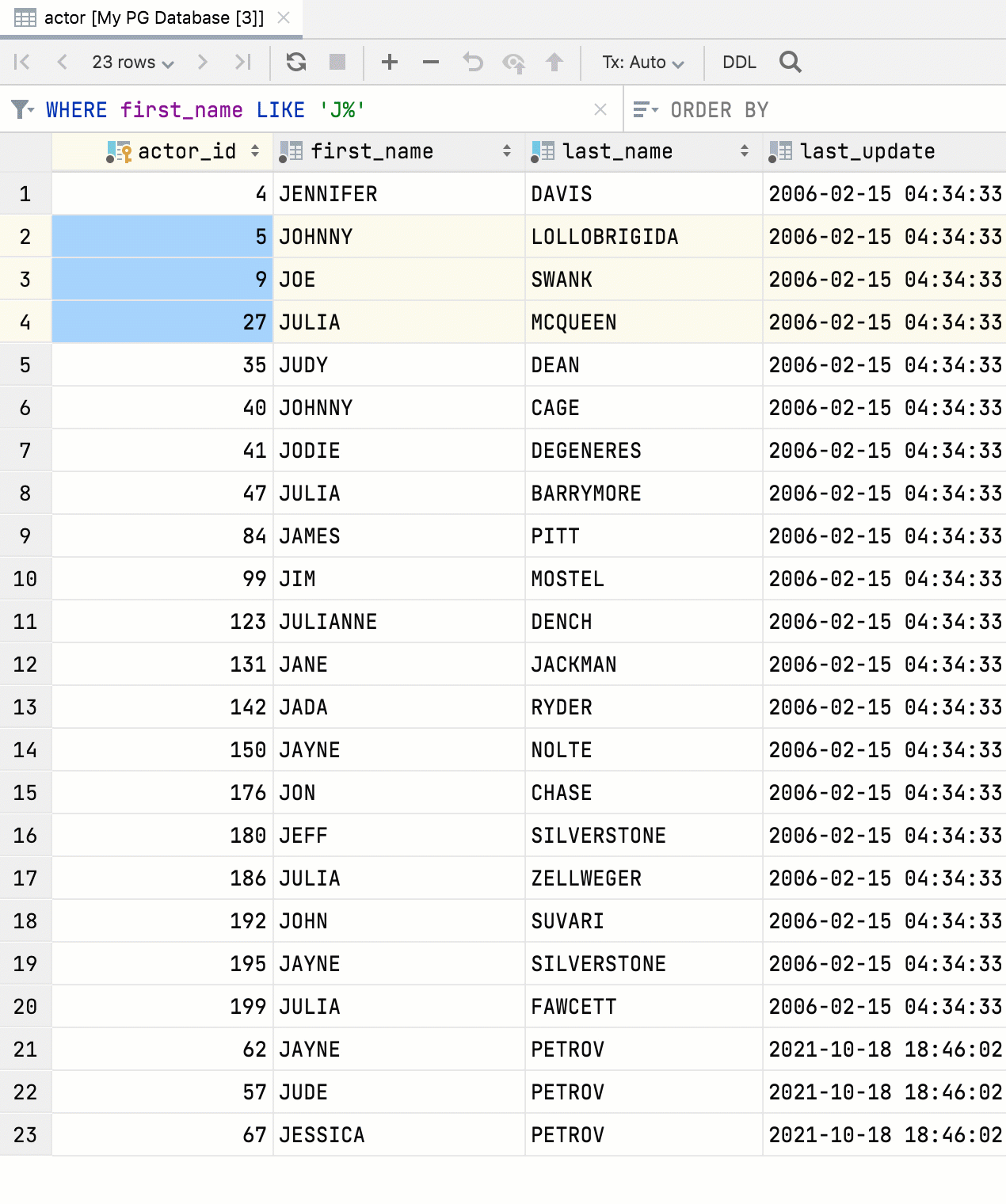 Foreign key navigation by several values In the data editor, you can now select several values and navigate to the related data.
Foreign key navigation by several values In the data editor, you can now select several values and navigate to the related data.
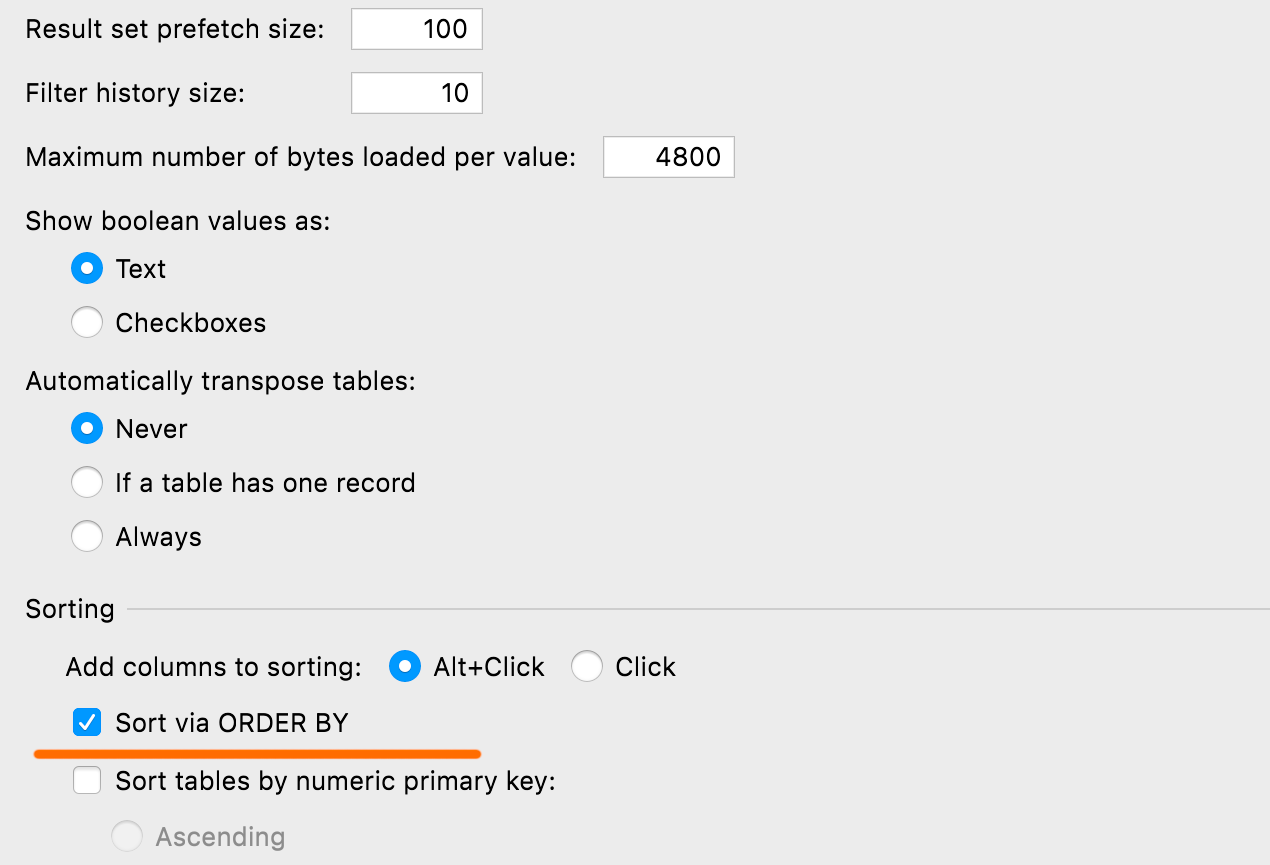 Setting for default sorting You can define the default method for sorting tables via ORDER BY or client-side: the latter doesn’t run any new queries and sorts only the current page. The setting can be found under Database | Data views | Sorting | Sort via ORDER BY.
Setting for default sorting You can define the default method for sorting tables via ORDER BY or client-side: the latter doesn’t run any new queries and sorts only the current page. The setting can be found under Database | Data views | Sorting | Sort via ORDER BY.
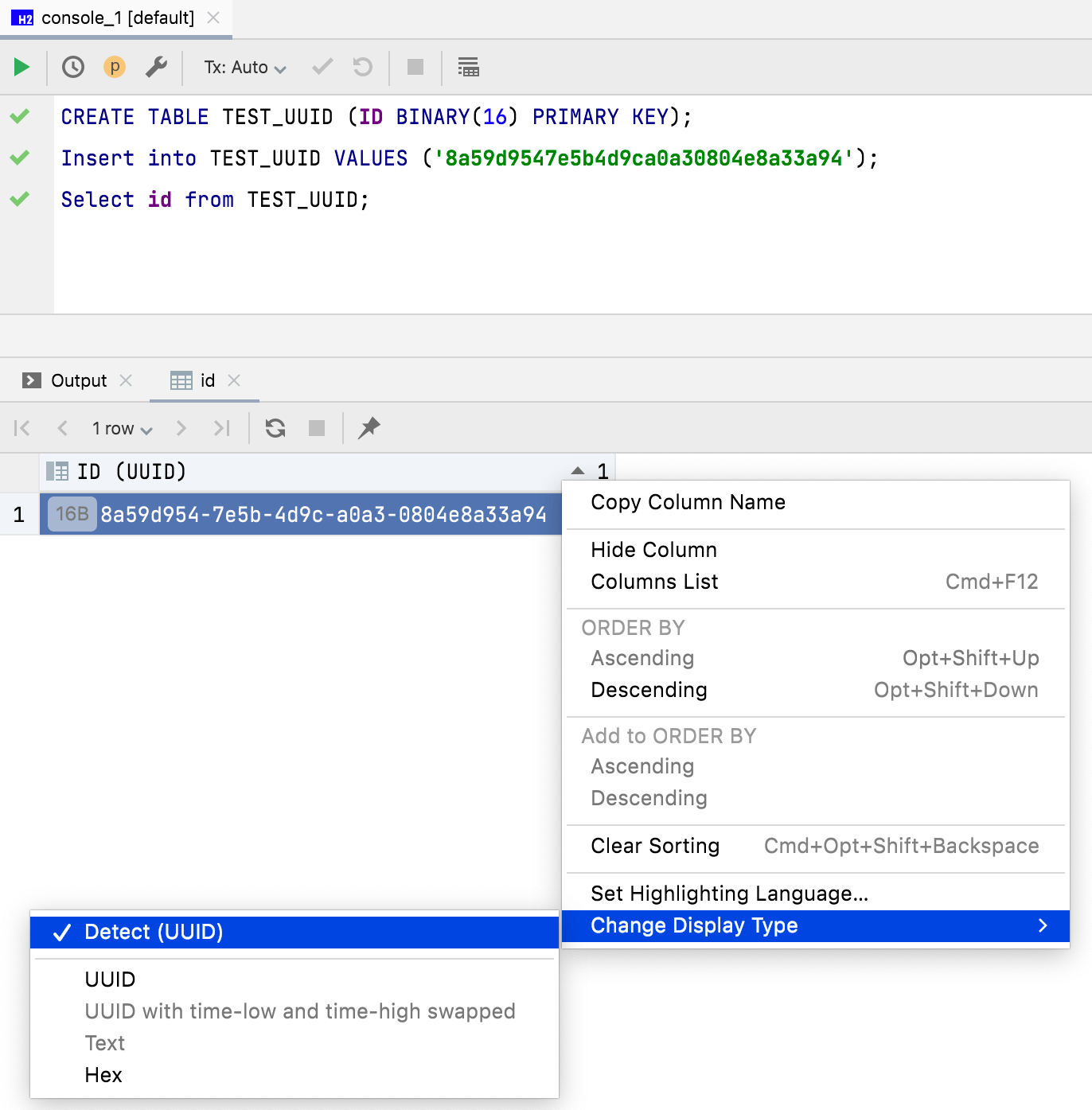 Display mode for binary data 16-byte data is now displayed as UUID by default. You can also customize how binary data is displayed in the data editor column.
Display mode for binary data 16-byte data is now displayed as UUID by default. You can also customize how binary data is displayed in the data editor column.
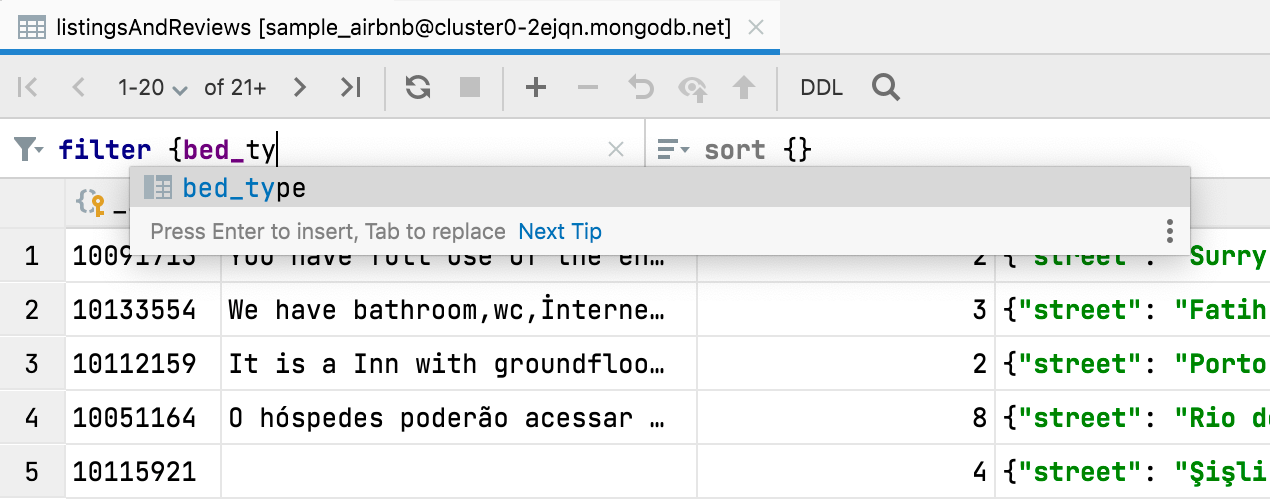 Completion for and MongoDB Code completion is now available when you’re filtering data in MongoDB collections. Keeping your database in the VCS
Completion for and MongoDB Code completion is now available when you’re filtering data in MongoDB collections. Keeping your database in the VCS
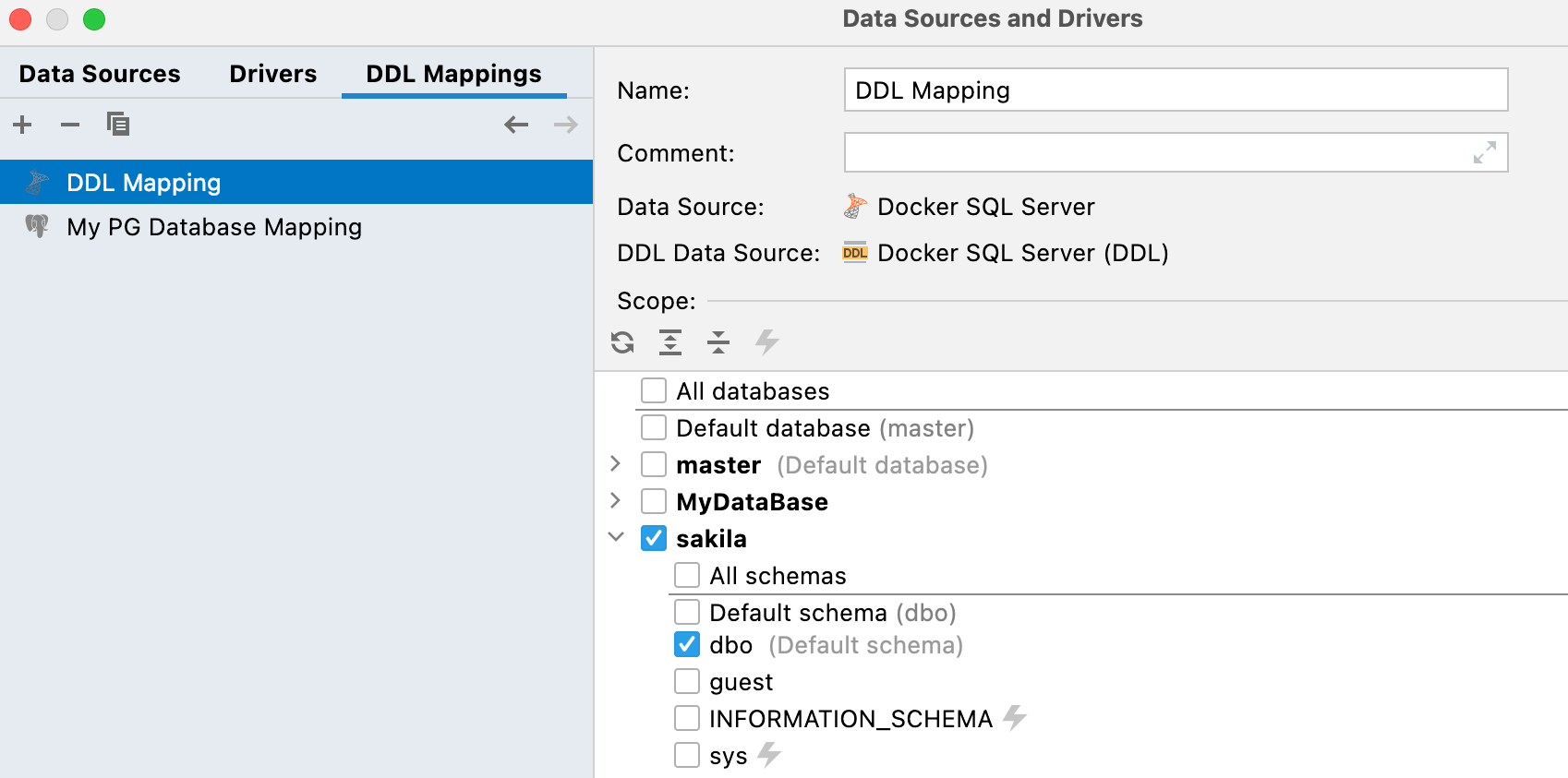 Mapping the DDL data source and the real one This release is a logical continuation of the previous one, which introduced the ability to generate a DDL data source based on a real one. Now, this workflow is fully supported. You can: Generate a DDL data source from a real one: see the 2021.2 announcement. Use the DDL data source to map the real one. Compare and synchronize them in both directions. Just as a reminder, a DDL data source is a virtual data source whose schema is based on a set of SQL scripts. Storing these files in the Version Control System is a way to keep your database under the VCS. There is a new tab in the data configuration properties, DDL mappings, where you can define which real data source is mapped to each DDL data source. If you want to know more about how exactly these new features will help you in your daily VCS flow, please read this article.
Mapping the DDL data source and the real one This release is a logical continuation of the previous one, which introduced the ability to generate a DDL data source based on a real one. Now, this workflow is fully supported. You can: Generate a DDL data source from a real one: see the 2021.2 announcement. Use the DDL data source to map the real one. Compare and synchronize them in both directions. Just as a reminder, a DDL data source is a virtual data source whose schema is based on a set of SQL scripts. Storing these files in the Version Control System is a way to keep your database under the VCS. There is a new tab in the data configuration properties, DDL mappings, where you can define which real data source is mapped to each DDL data source. If you want to know more about how exactly these new features will help you in your daily VCS flow, please read this article.
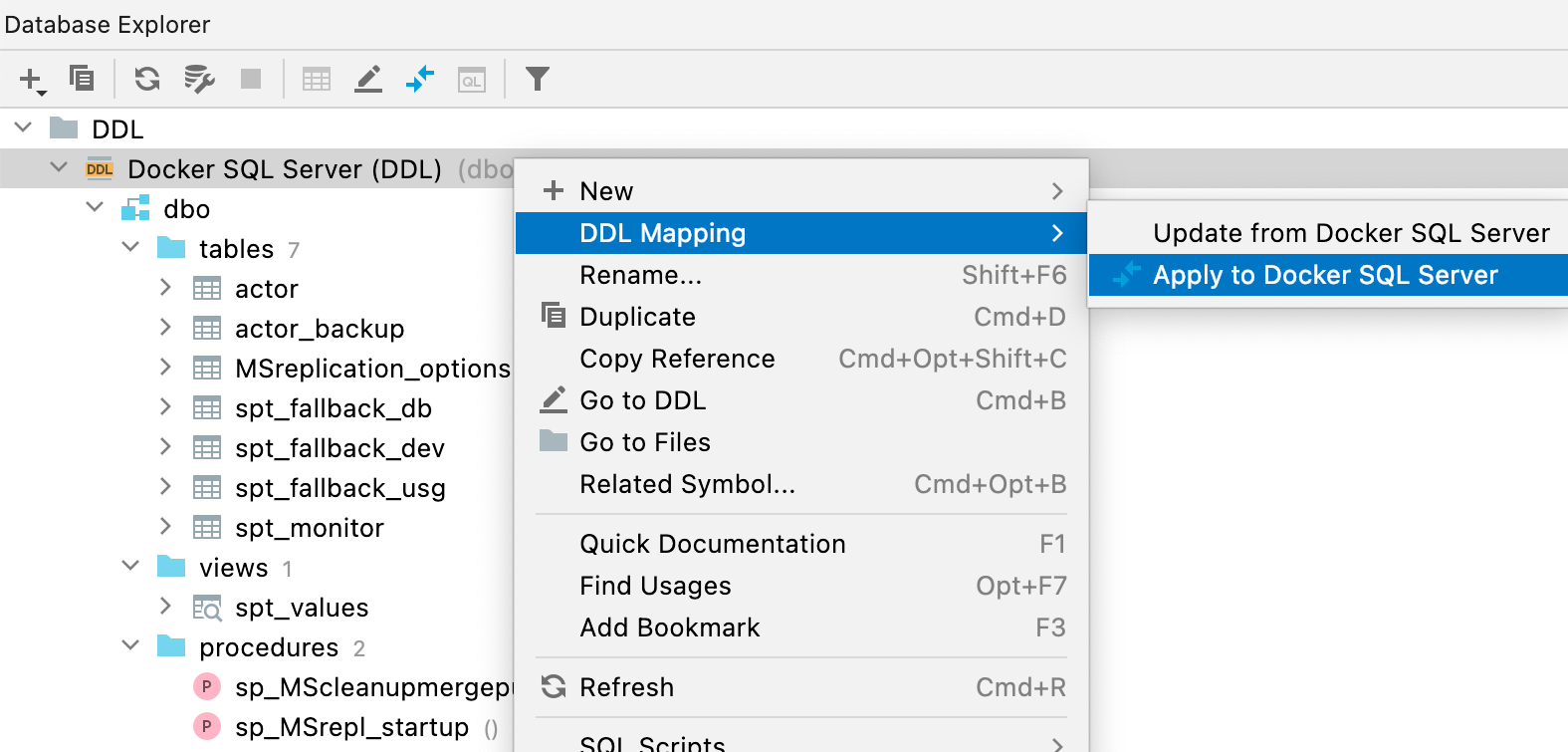 New database diff window To compare and synchronize your DDL data source with the real one, use the context menu and select Apply from... or Dump to... from the DDL Mappings submenu.
New database diff window To compare and synchronize your DDL data source with the real one, use the context menu and select Apply from... or Dump to... from the DDL Mappings submenu.
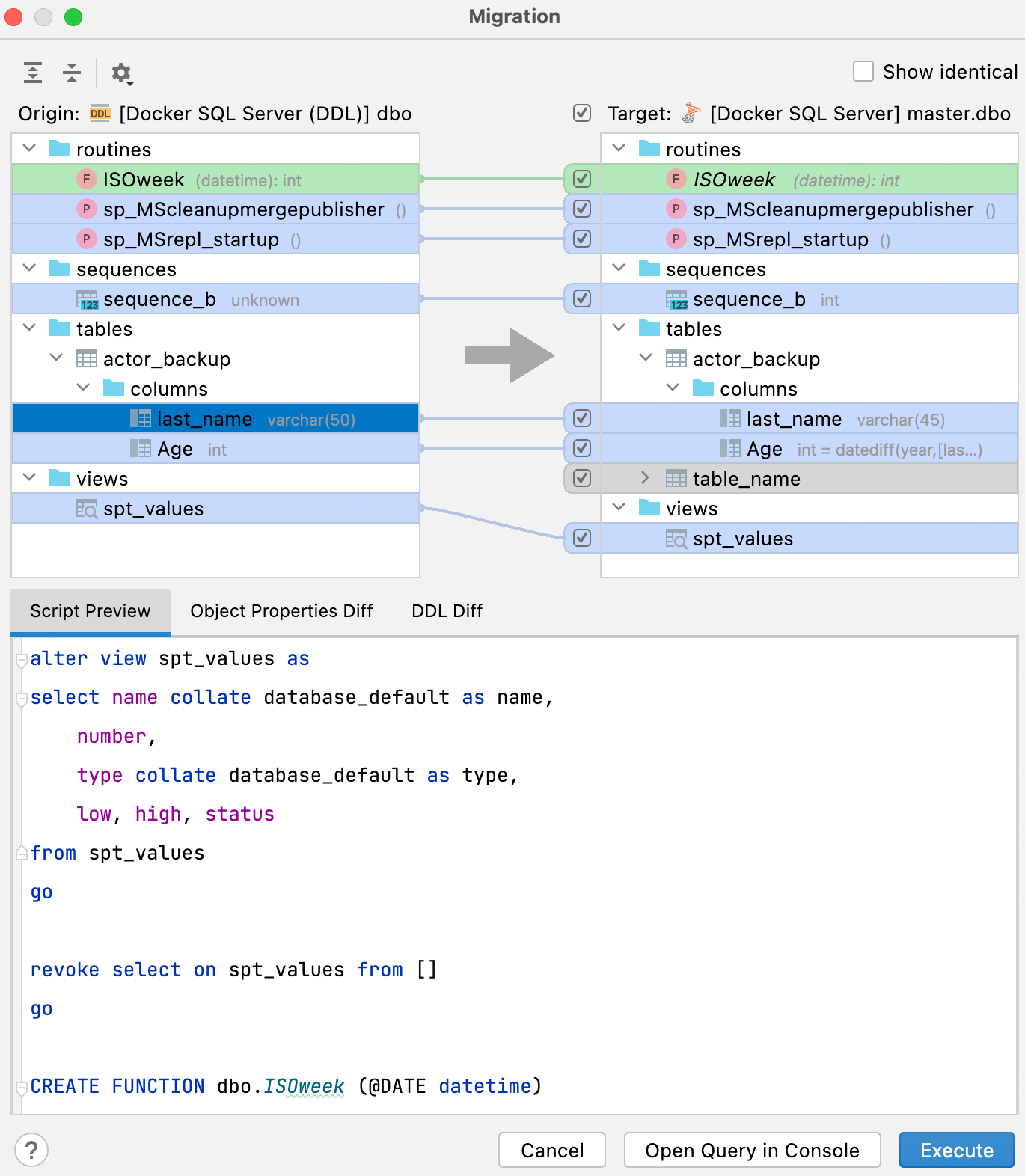 This brand-new window has a better UI and clearly shows in the right-hand pane what result you’ll get after you perform the synchronization.
This brand-new window has a better UI and clearly shows in the right-hand pane what result you’ll get after you perform the synchronization.
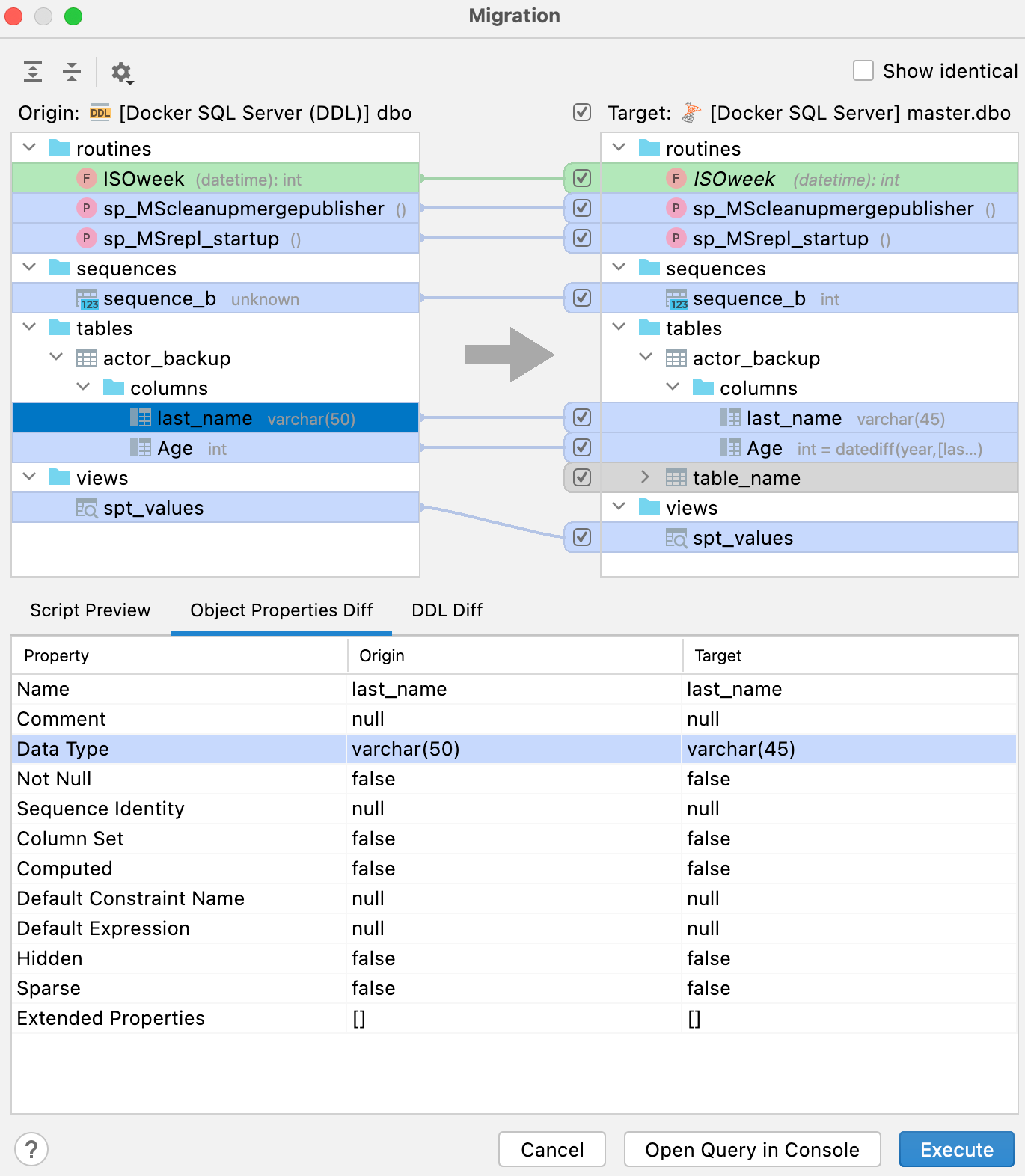 The legend in the right-hand pane shows what the colors mean for your potential result: Green and italic: object will be created. Grey: object will be deleted. Blue: object will be changed. The Script preview tab shows the result script, which can be either opened in a new console or run from this dialog. The result of this script is applying changes to make the database on the right (target) a copy of the database on the left (source). Besides the Script preview tab, there are two more tabs on the bottom pane: Object Properties Diff and DDL Diff. They display the difference between the particular versions of the object in the origin and in the target databases. Just a reminder: if you want to merely compare two schemas or objects, select them and press Ctrl + D. Important! The diff viewer is still under heavy development. Because each database has its own specific features, some objects may display as different while they are, in fact, identical. This may happen because of type aliases or omitting the default properties in the generation. If you come across this bug, please report it to our tracker.
The legend in the right-hand pane shows what the colors mean for your potential result: Green and italic: object will be created. Grey: object will be deleted. Blue: object will be changed. The Script preview tab shows the result script, which can be either opened in a new console or run from this dialog. The result of this script is applying changes to make the database on the right (target) a copy of the database on the left (source). Besides the Script preview tab, there are two more tabs on the bottom pane: Object Properties Diff and DDL Diff. They display the difference between the particular versions of the object in the origin and in the target databases. Just a reminder: if you want to merely compare two schemas or objects, select them and press Ctrl + D. Important! The diff viewer is still under heavy development. Because each database has its own specific features, some objects may display as different while they are, in fact, identical. This may happen because of type aliases or omitting the default properties in the generation. If you come across this bug, please report it to our tracker.
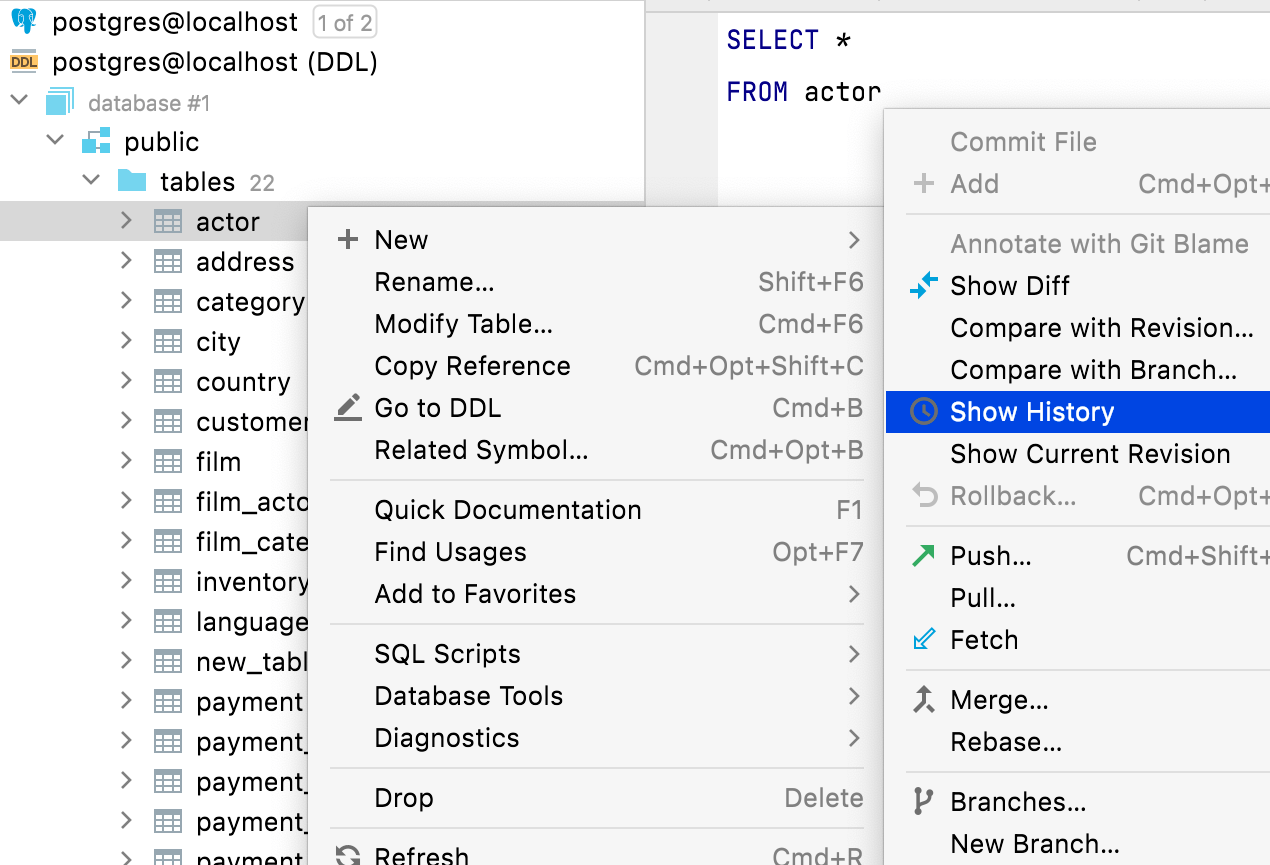 File-related actions All actions for files are available on DDL data source elements as well. For example, you can delete, copy, or commit files related to the schema elements from the database explorer.
File-related actions All actions for files are available on DDL data source elements as well. For example, you can delete, copy, or commit files related to the schema elements from the database explorer.
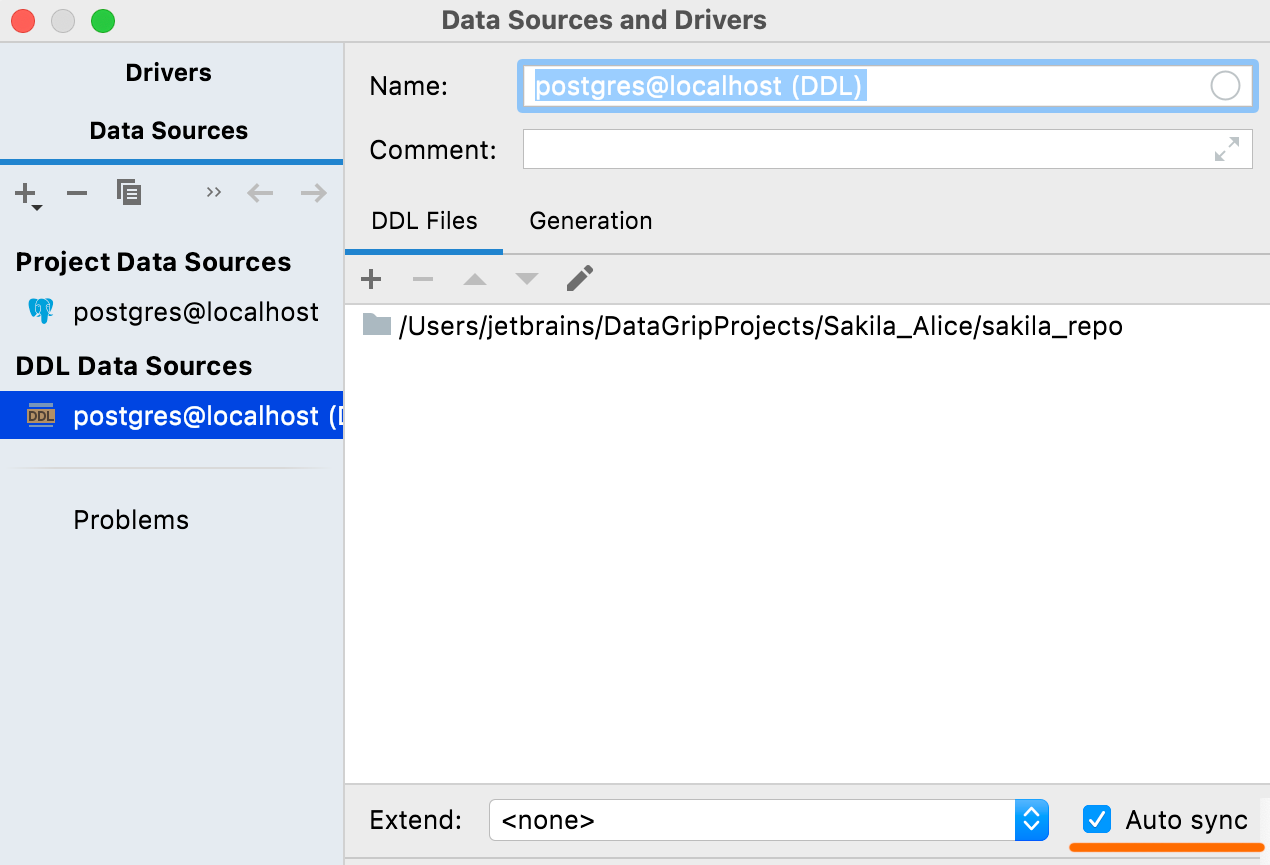 Auto-sync If this option is turned on, your DDL data source will be automatically refreshed with changes to the corresponding files. This was already the default behavior, but now you have the option to disable it. If you do disable it, changes in the source files will not automatically be reflected in the DDL data source, so you'll need to click Refresh to apply them.
Auto-sync If this option is turned on, your DDL data source will be automatically refreshed with changes to the corresponding files. This was already the default behavior, but now you have the option to disable it. If you do disable it, changes in the source files will not automatically be reflected in the DDL data source, so you'll need to click Refresh to apply them.
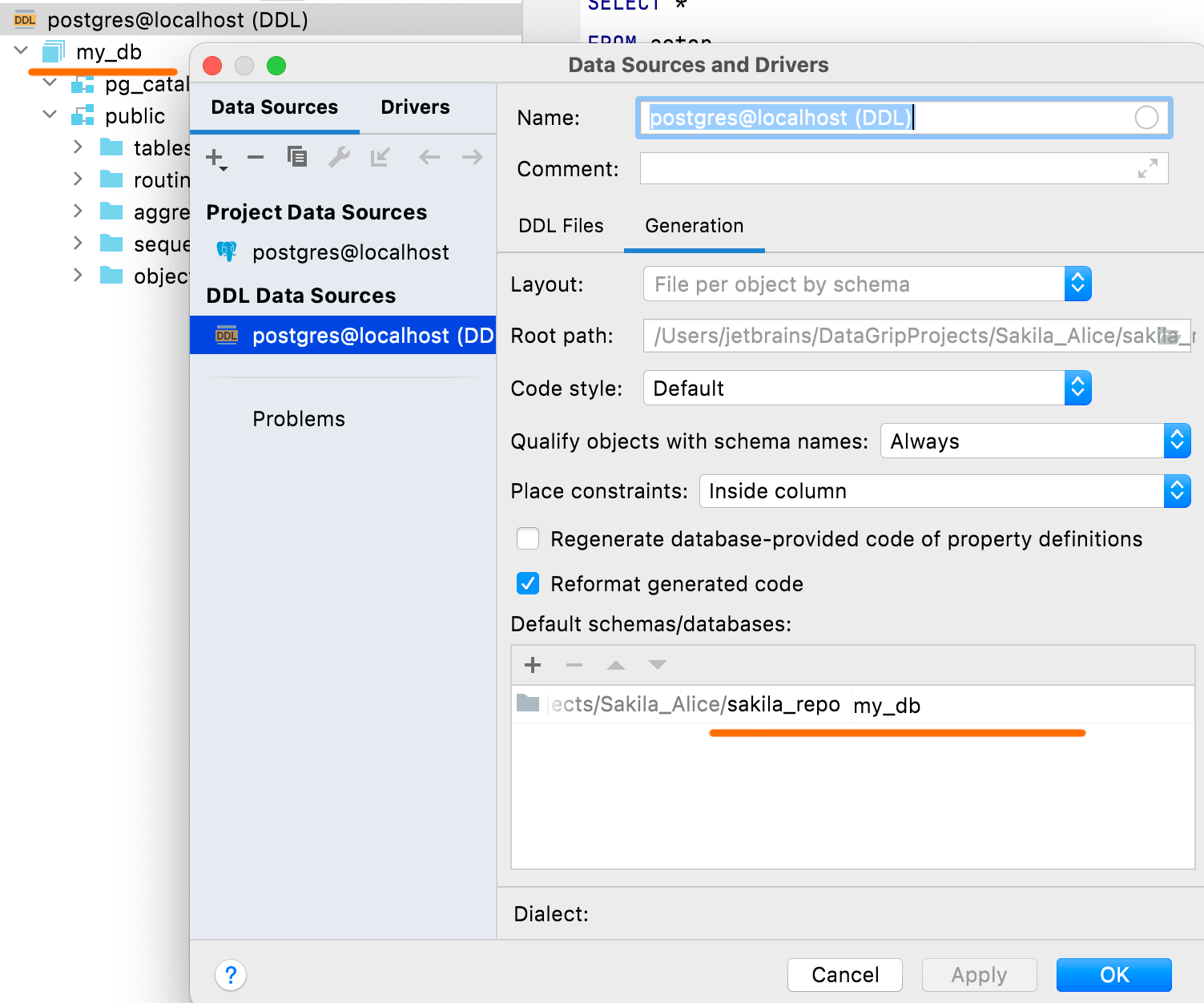 Setting the default schemas and databases In the Default schemas/databases pane you can define names for your database and schemas, which will be displayed in the DDL data source. DDL scripts don’t usually contain names, and in these cases there will be dummy names for databases and schemas by default. Connectivity
Setting the default schemas and databases In the Default schemas/databases pane you can define names for your database and schemas, which will be displayed in the DDL data source. DDL scripts don’t usually contain names, and in these cases there will be dummy names for databases and schemas by default. Connectivity
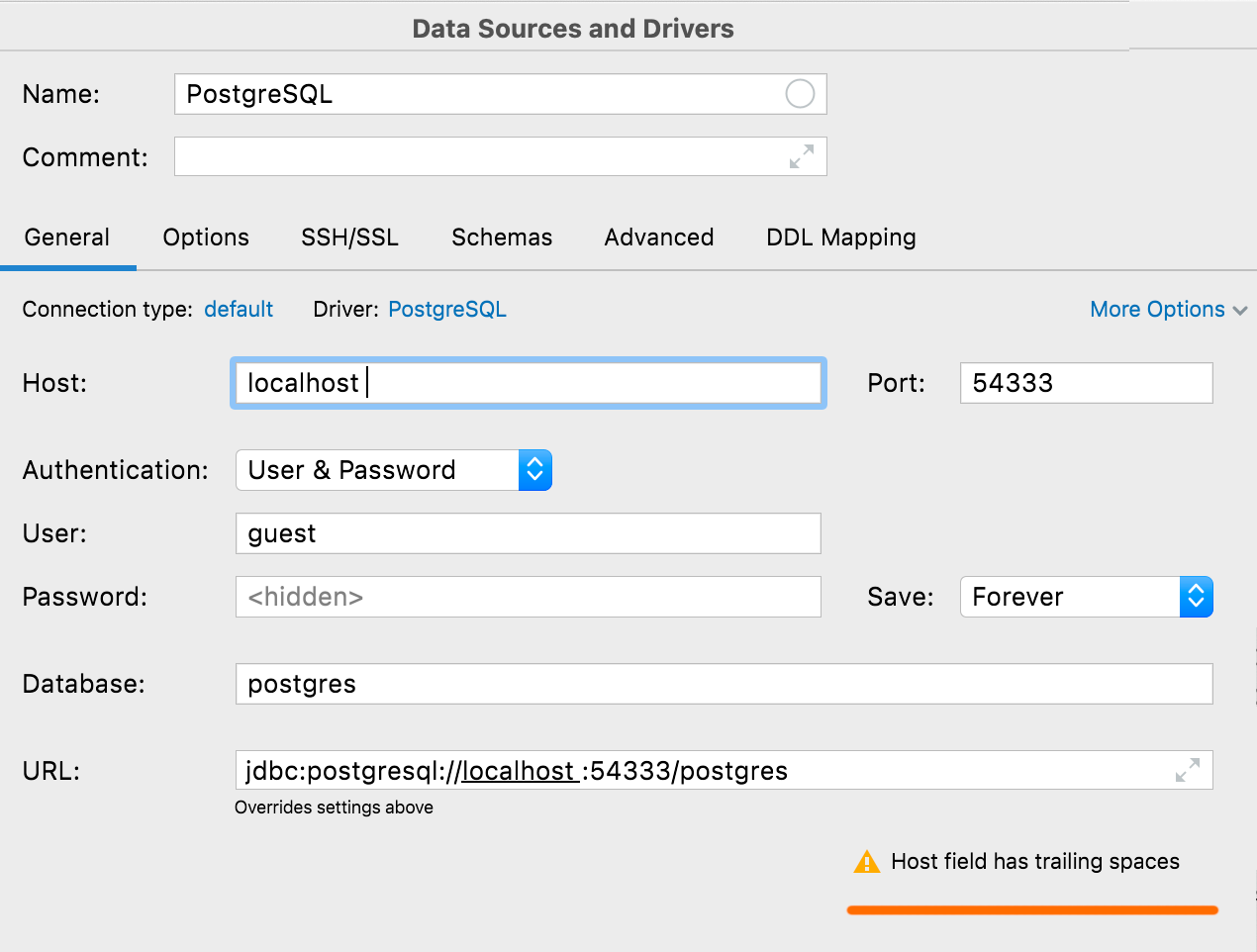 Accidental spaces warning If any value except User or Password has leading or trailing spaces, DataGrip will warn you about them when you click Test Connection.
Accidental spaces warning If any value except User or Password has leading or trailing spaces, DataGrip will warn you about them when you click Test Connection.
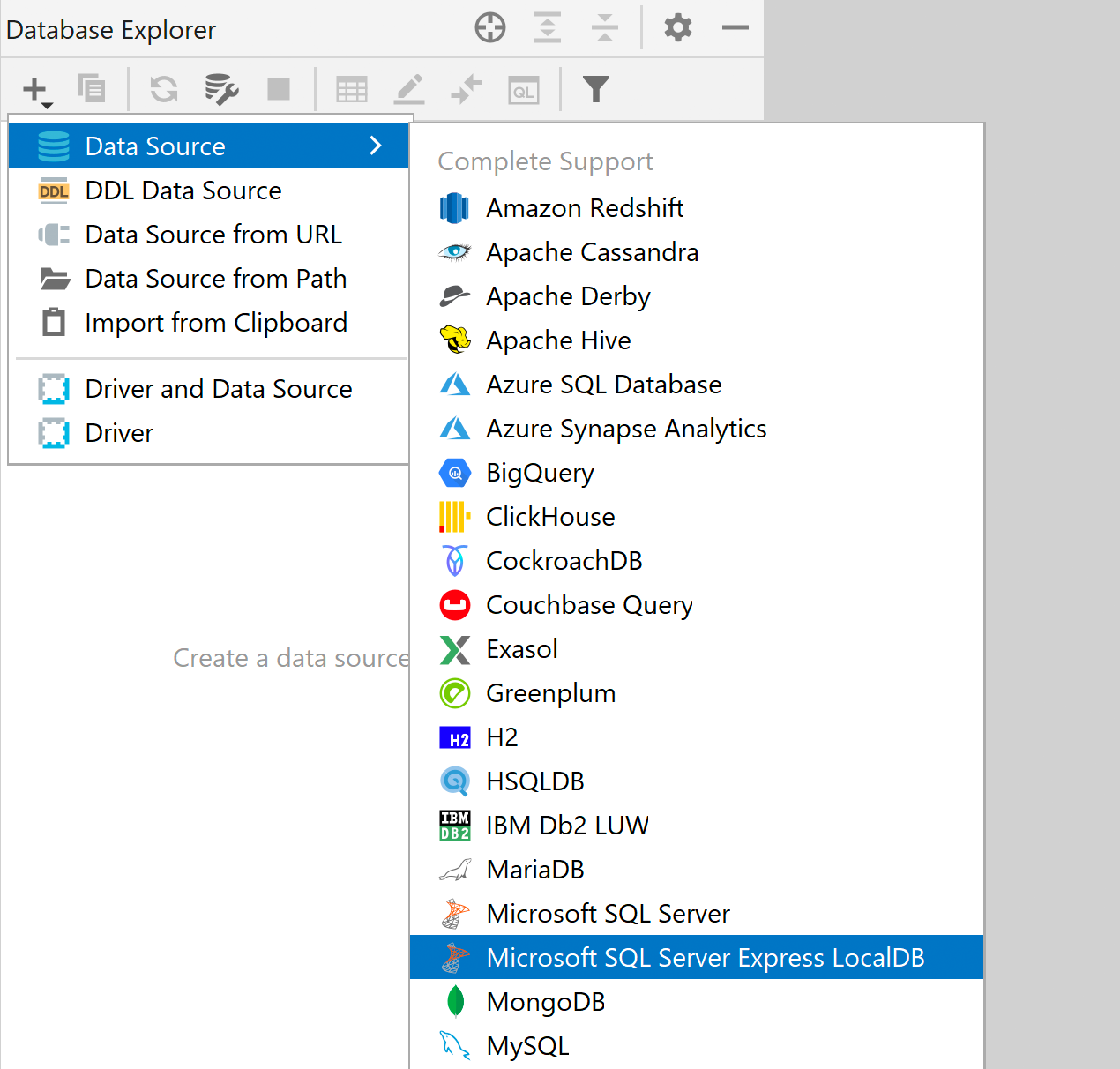 LocalDB as a dedicated data source SQL Server SQL Server LocalDB has its own dedicated driver in the driver list. This means that it has a separate type of data source which should be used for LocalDB. Here’s how it helps: The LocalDB connection is more explorable. You only need to set the path for the executable once, in the driver options, and it will be applied for all data sources.
LocalDB as a dedicated data source SQL Server SQL Server LocalDB has its own dedicated driver in the driver list. This means that it has a separate type of data source which should be used for LocalDB. Here’s how it helps: The LocalDB connection is more explorable. You only need to set the path for the executable once, in the driver options, and it will be applied for all data sources.
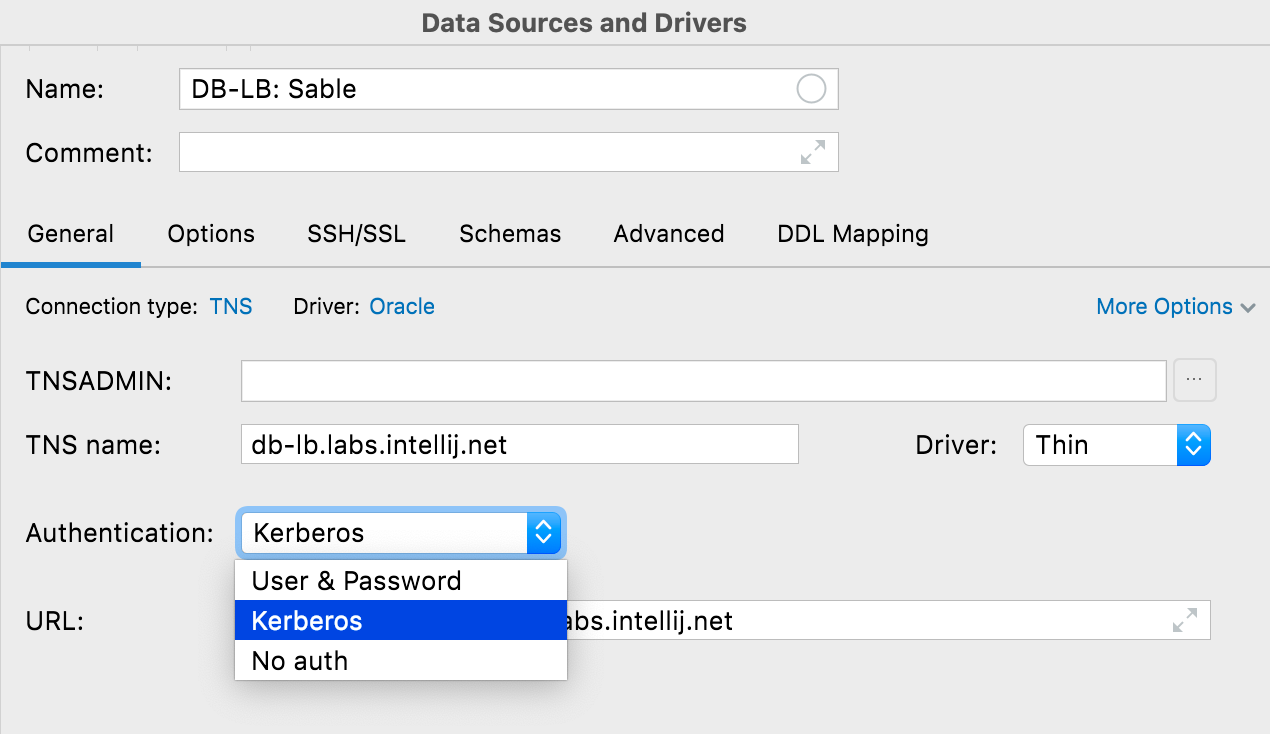 Kerberos authentication Oracle, SQL Server It’s now possible to use Kerberos authentication in Oracle and SQL Server. You need to obtain an initial ticket-granting ticket for the principal by using the kinit command, which DataGrip will use when you choose the Kerberos option.
Kerberos authentication Oracle, SQL Server It’s now possible to use Kerberos authentication in Oracle and SQL Server. You need to obtain an initial ticket-granting ticket for the principal by using the kinit command, which DataGrip will use when you choose the Kerberos option.
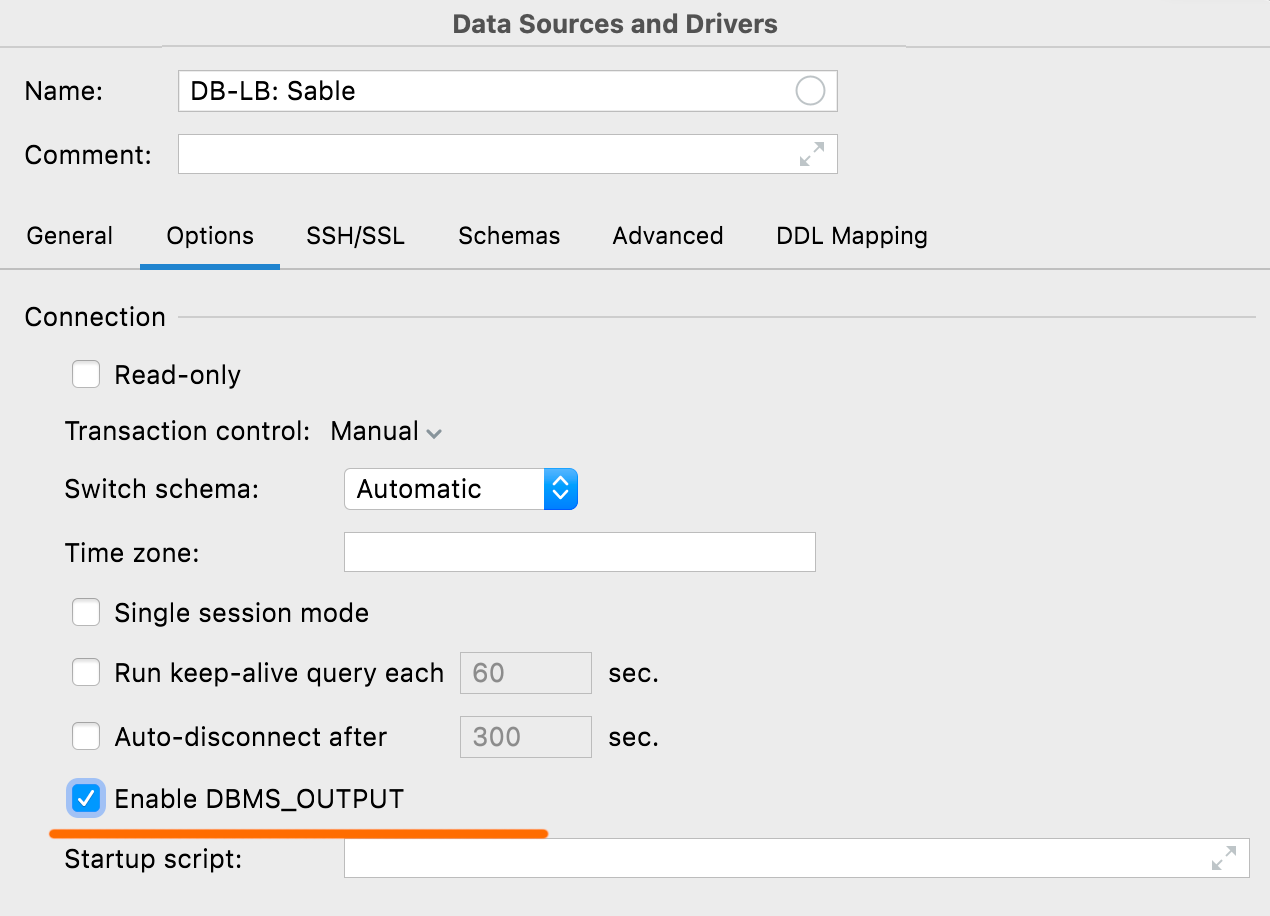 Enable DBMS_OUTPUT Oracle, IBM Db2 This new option in the Options tab lets you enable DBMS_OUTPUT by default for new sessions.
Enable DBMS_OUTPUT Oracle, IBM Db2 This new option in the Options tab lets you enable DBMS_OUTPUT by default for new sessions.
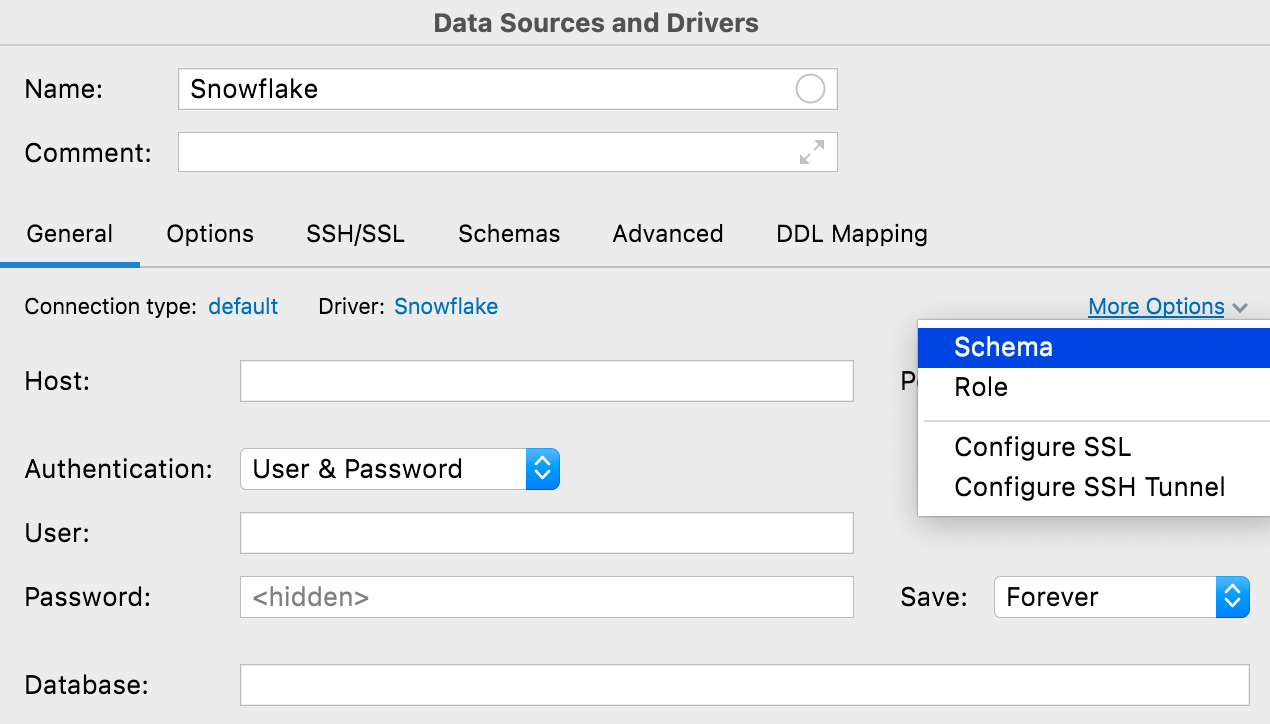 More options button We’ve added a More Options button for when you need to configure something unusual for a connection. The currently available options include the ability to add Schema and Role fields for Snowflake connections, and two menu items for configuring SSH and SSL to increase their discoverability.
More options button We’ve added a More Options button for when you need to configure something unusual for a connection. The currently available options include the ability to add Schema and Role fields for Snowflake connections, and two menu items for configuring SSH and SSL to increase their discoverability.
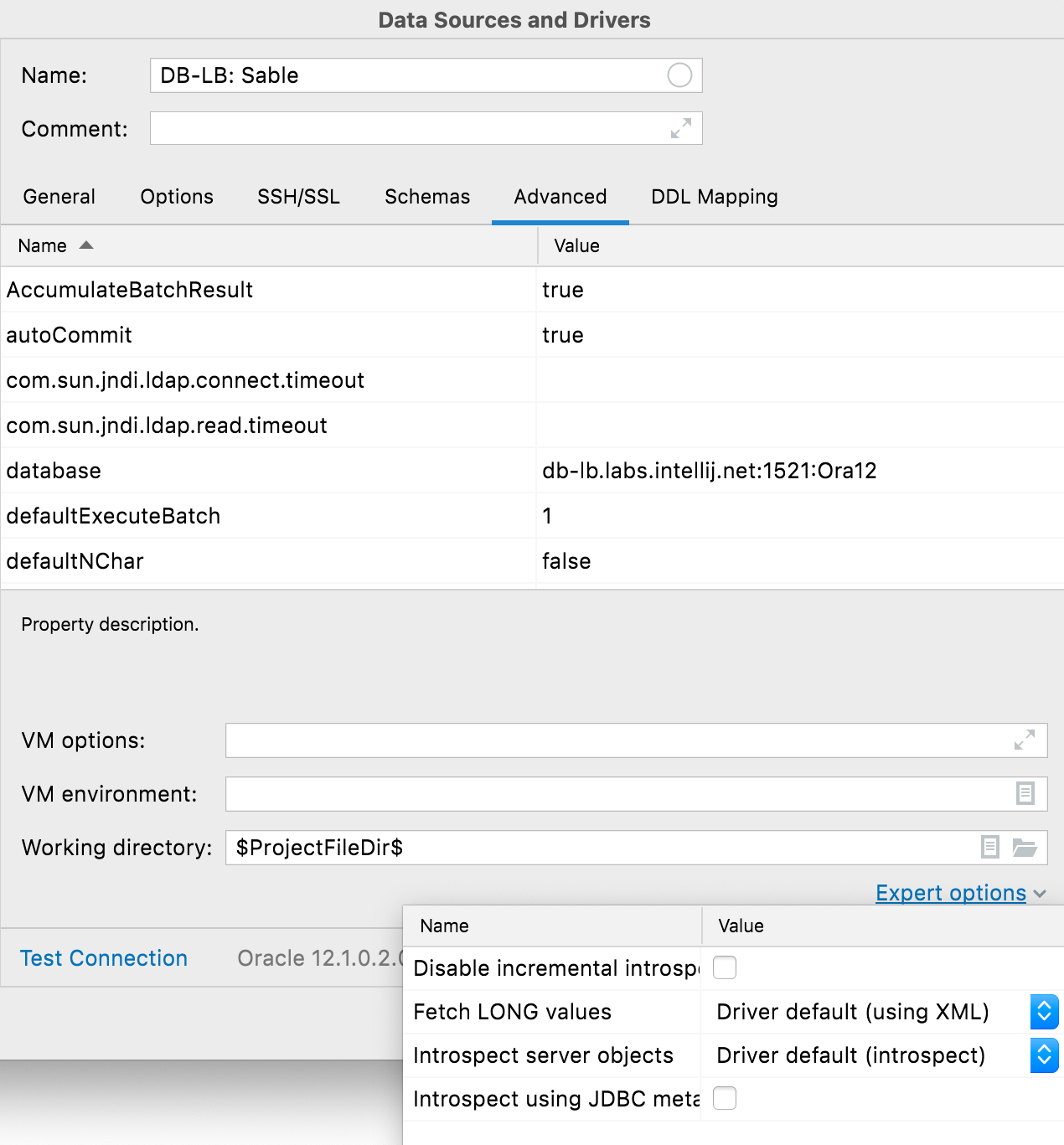 Expert options The Advanced tab now includes a list of Expert options. In addition to the option to turn on the JDBC introspector (please contact our support before using this!), the following database-specific options are available: Oracle: Disable incremental introspection, Fetch LONG values, and Introspect server objects SQL Server: Disable incremental introspection PostgreSQL (and similar): Disable incremental introspection and Do not use xmin in queries to pgdatabase SQLite: Register REGEXP function MYSQL: Use SHOW/CREATE for source code ClickHouse: Automatically assign sessionid Introspection Introspection levels Oracle Oracle users have been experiencing a problem with DataGrip’s introspection, which took a long time if they had lots of databases and schemas. Introspection is the process of getting the metadata of the database, such as object names and source code. DataGrip needs it to provide rapid coding assistance, navigation, and search. Oracle system catalogs are rather slow, and the introspection was even slower if the user had no admin rights. We did our best to optimize the queries to get the metadata, but everything has its limitations. We realized that for most daily work, and even for effective coding assistance, there is no need to load object sources. In many cases, just having database object names should be sufficient to provide proper code completion and navigation. So, we introduced three levels of introspection for Oracle databases: Level 1: Names of all supported objects and their signatures, excluding names of index columns and private package variables Level 2: Everything except source code Level 3: Everything Introspection is fastest on level 1 and slowest on level 3.
Expert options The Advanced tab now includes a list of Expert options. In addition to the option to turn on the JDBC introspector (please contact our support before using this!), the following database-specific options are available: Oracle: Disable incremental introspection, Fetch LONG values, and Introspect server objects SQL Server: Disable incremental introspection PostgreSQL (and similar): Disable incremental introspection and Do not use xmin in queries to pgdatabase SQLite: Register REGEXP function MYSQL: Use SHOW/CREATE for source code ClickHouse: Automatically assign sessionid Introspection Introspection levels Oracle Oracle users have been experiencing a problem with DataGrip’s introspection, which took a long time if they had lots of databases and schemas. Introspection is the process of getting the metadata of the database, such as object names and source code. DataGrip needs it to provide rapid coding assistance, navigation, and search. Oracle system catalogs are rather slow, and the introspection was even slower if the user had no admin rights. We did our best to optimize the queries to get the metadata, but everything has its limitations. We realized that for most daily work, and even for effective coding assistance, there is no need to load object sources. In many cases, just having database object names should be sufficient to provide proper code completion and navigation. So, we introduced three levels of introspection for Oracle databases: Level 1: Names of all supported objects and their signatures, excluding names of index columns and private package variables Level 2: Everything except source code Level 3: Everything Introspection is fastest on level 1 and slowest on level 3.
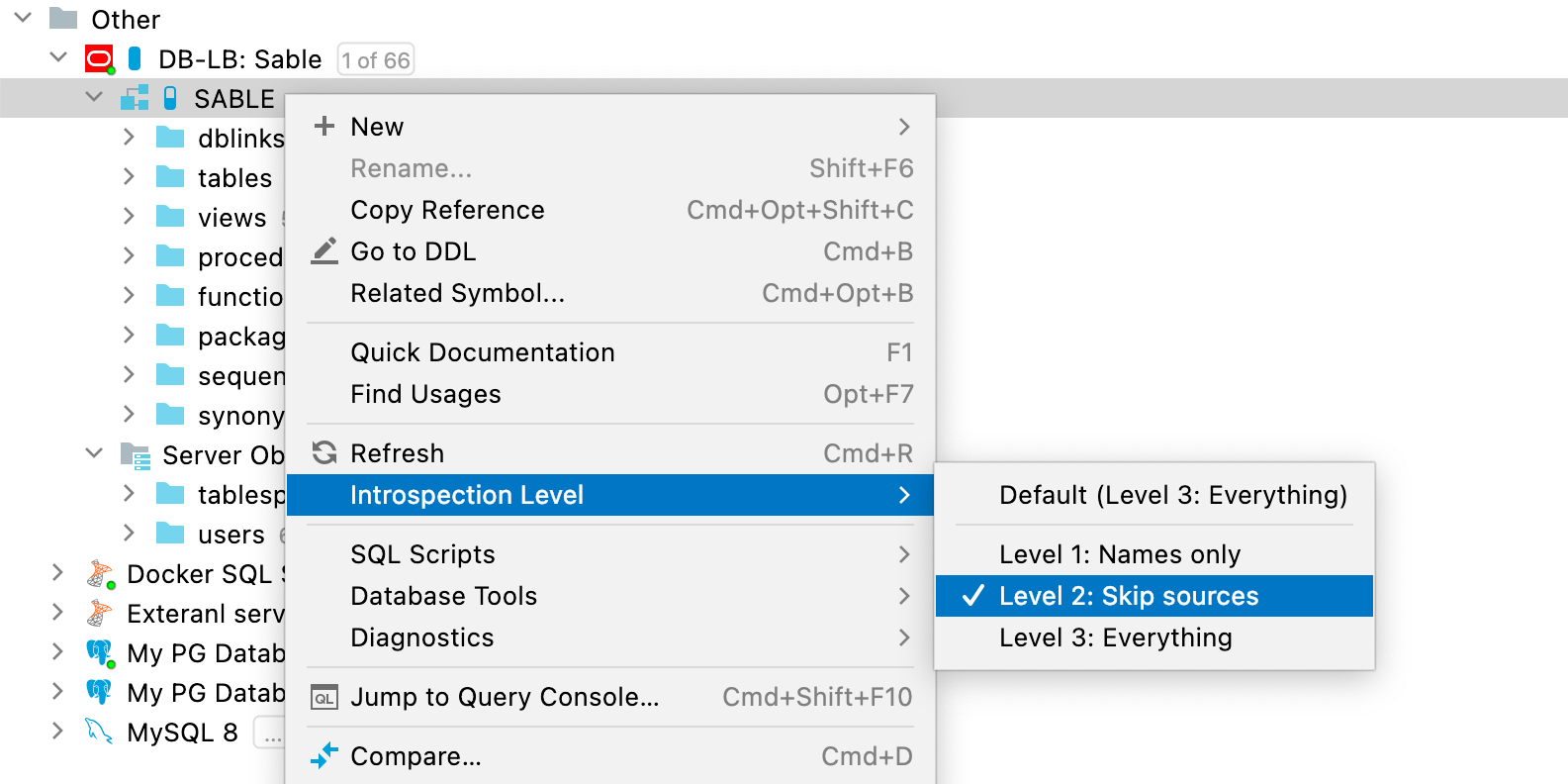 Use the context menu to switch the introspection level as appropriate:
Use the context menu to switch the introspection level as appropriate:
 The introspection level can be set either for a schema or for the whole database. Schemas inherit their introspection level from the database, but it also can be set independently. The introspection level is represented by the pill-looking icons located next to the data source icon. The more the pill is filled, the higher the level. A blue icon means that the introspection level is set directly, while a grey one means that it is inherited.
The introspection level can be set either for a schema or for the whole database. Schemas inherit their introspection level from the database, but it also can be set independently. The introspection level is represented by the pill-looking icons located next to the data source icon. The more the pill is filled, the higher the level. A blue icon means that the introspection level is set directly, while a grey one means that it is inherited.
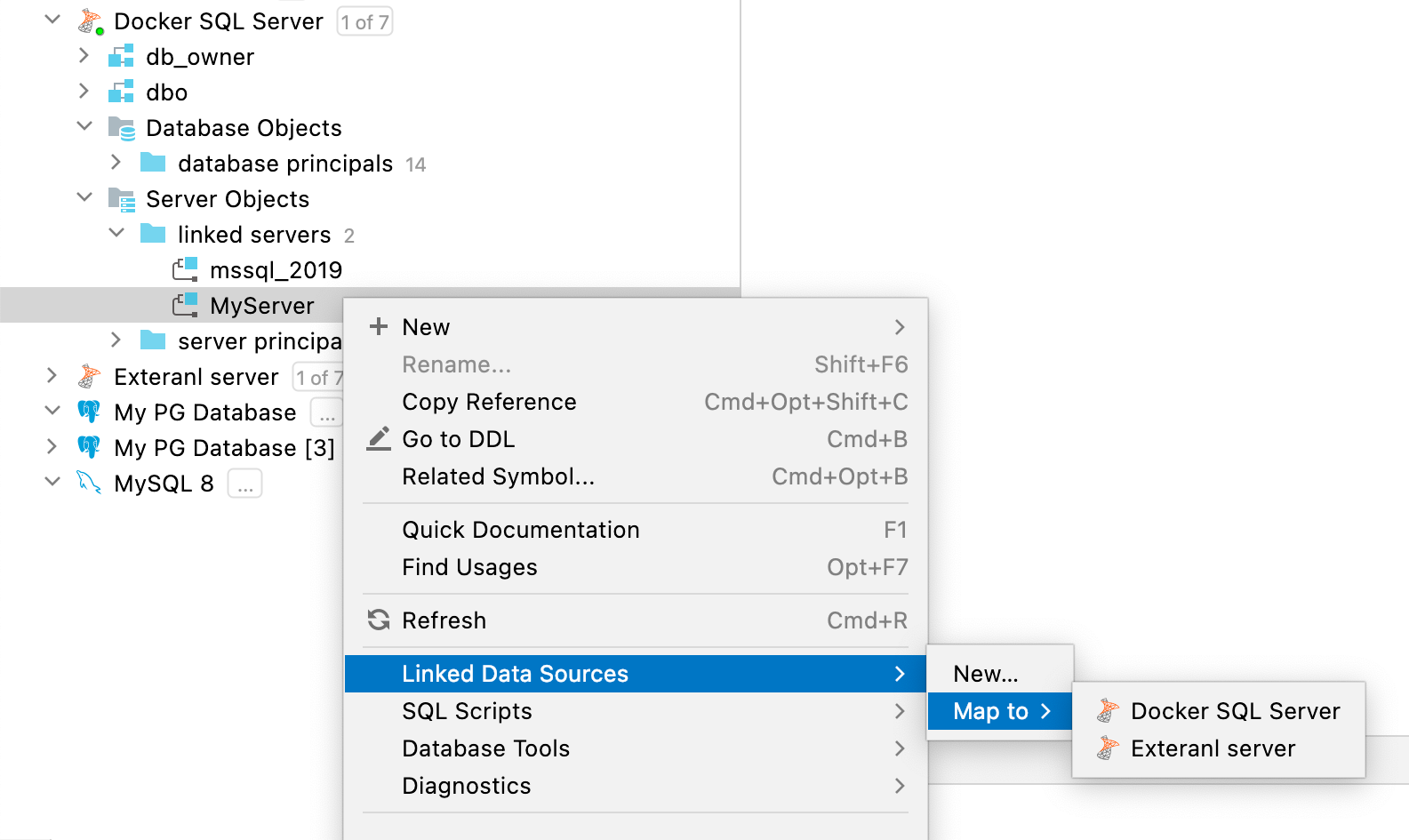 Mapping linked servers and database links to data sources SQL Server, Oracle You can map your linked server in SQL Server or database link in Oracle to any existing data source.
Mapping linked servers and database links to data sources SQL Server, Oracle You can map your linked server in SQL Server or database link in Oracle to any existing data source.
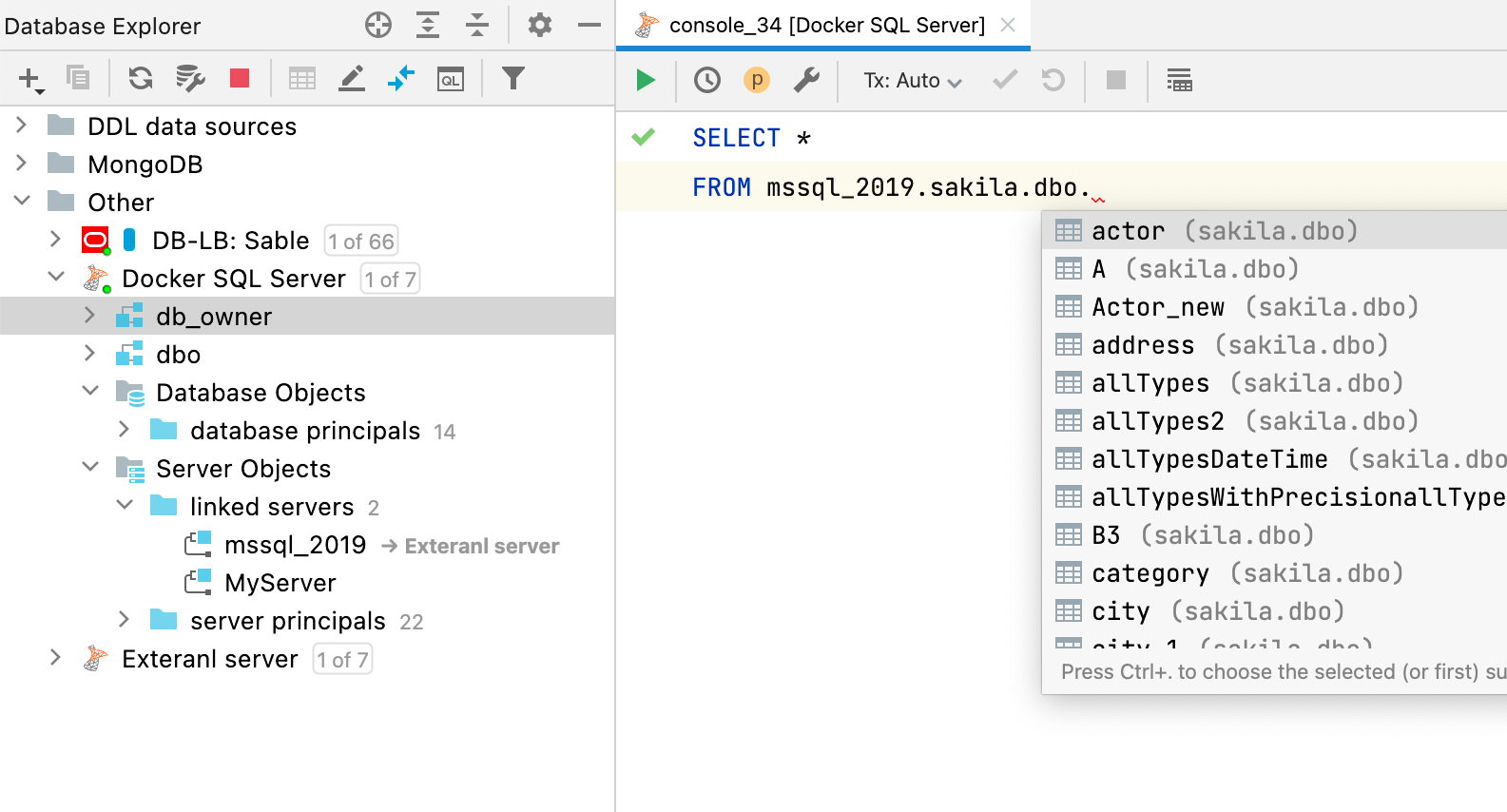 When external objects are mapped to the data source, the code completion and resolve will work for queries using those external objects.
When external objects are mapped to the data source, the code completion and resolve will work for queries using those external objects.
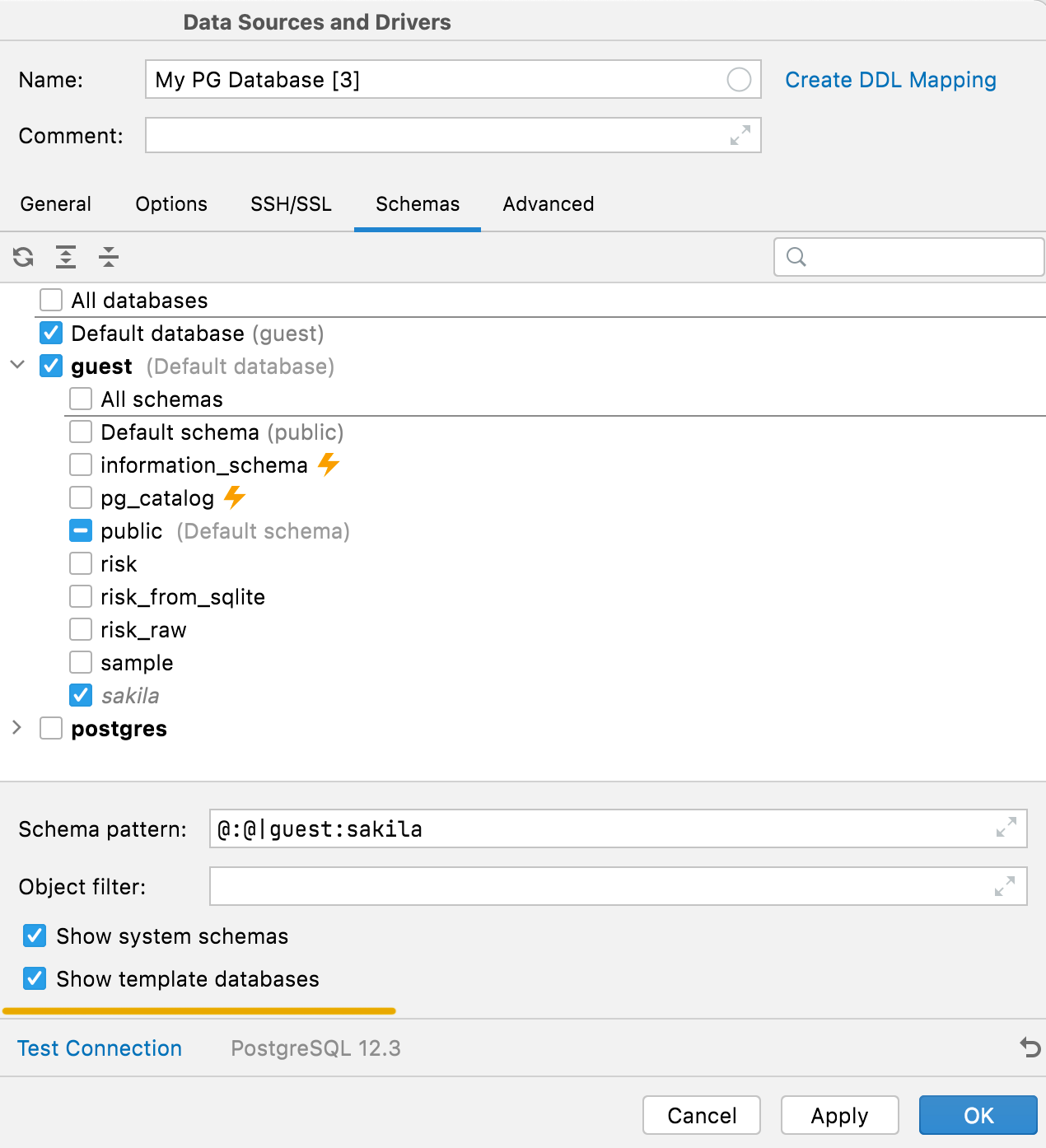 Hide system schemas and template databases PostgreSQL Internal system schemas (like pg_toast or pg_temp) and template databases used to be hidden from the schemas list. Now it’s possible to show them by using the corresponding options in the Schemas tab.
Hide system schemas and template databases PostgreSQL Internal system schemas (like pg_toast or pg_temp) and template databases used to be hidden from the schemas list. Now it’s possible to show them by using the corresponding options in the Schemas tab.
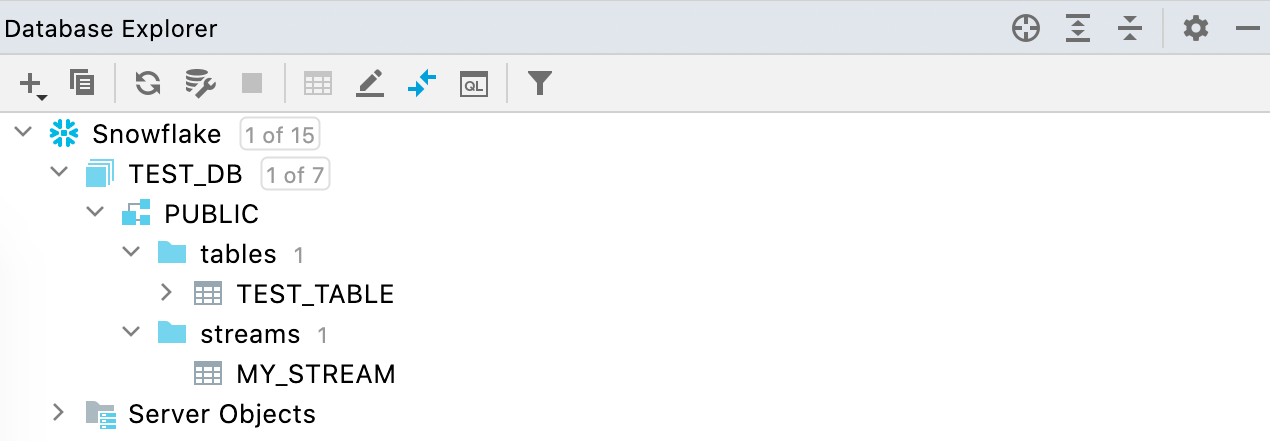 Support for streams Snowflake Now, streams are displayed in the database view in addition to tables and views.
Support for streams Snowflake Now, streams are displayed in the database view in addition to tables and views.
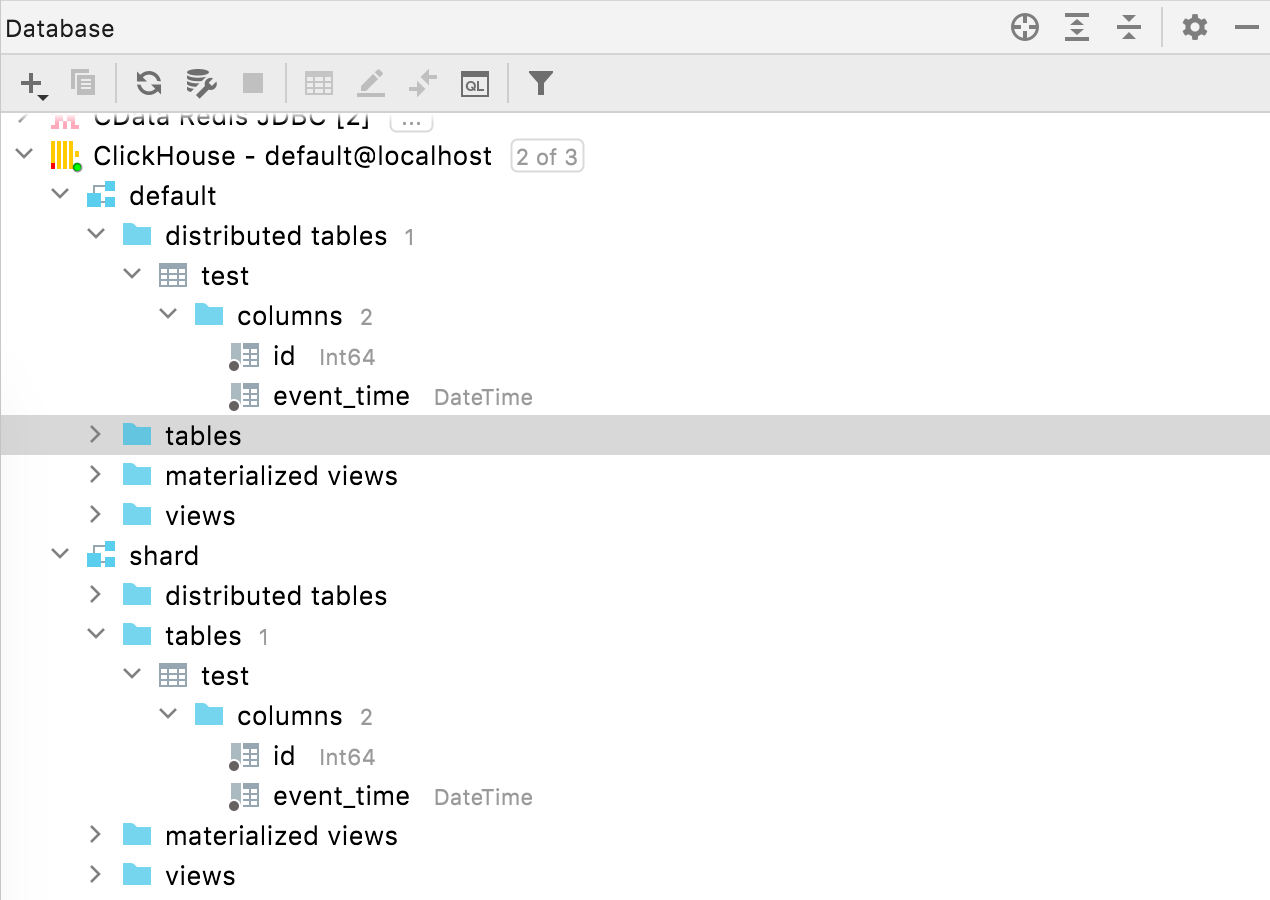 Distributed tables ClickHouse Distributed tables are now placed under a dedicated node in the database explorer. Query Console
Distributed tables ClickHouse Distributed tables are now placed under a dedicated node in the database explorer. Query Console
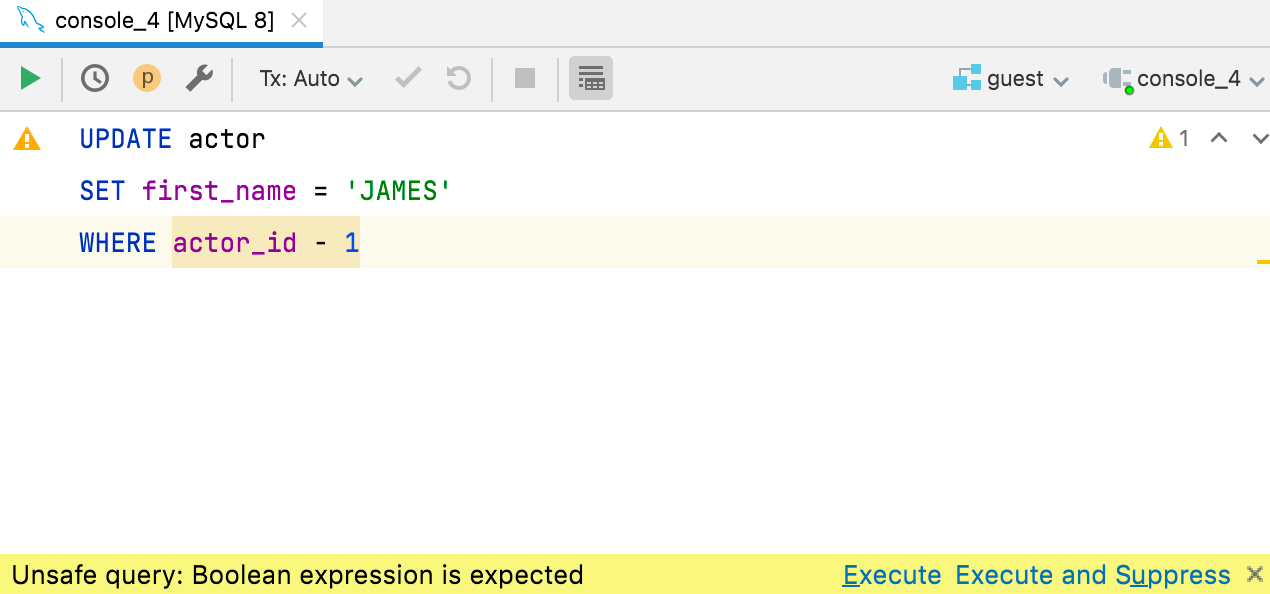 Check for boolean expressions One of our users posted about an unfortunate situation: he executed the query on a production database with the condition (instead of =) and had millions of records updated! We were also surprised that MySQL allows that, but such is life. But we wouldn’t be the DataGrip team if we didn’t add an inspection for that! Please welcome the check for boolean expressions in and clauses. If the expression doesn’t seem to be explicitly boolean, DataGrip will highlight it in yellow and will warn you before you run such a query. It works for ClickHouse, Couchbase, Db2, H2, Hive/Spark, MySQL/MariaDB, Redshift, SQLite, and Vertica. In all other databases, this will be highlighted as an error.
Check for boolean expressions One of our users posted about an unfortunate situation: he executed the query on a production database with the condition (instead of =) and had millions of records updated! We were also surprised that MySQL allows that, but such is life. But we wouldn’t be the DataGrip team if we didn’t add an inspection for that! Please welcome the check for boolean expressions in and clauses. If the expression doesn’t seem to be explicitly boolean, DataGrip will highlight it in yellow and will warn you before you run such a query. It works for ClickHouse, Couchbase, Db2, H2, Hive/Spark, MySQL/MariaDB, Redshift, SQLite, and Vertica. In all other databases, this will be highlighted as an error.
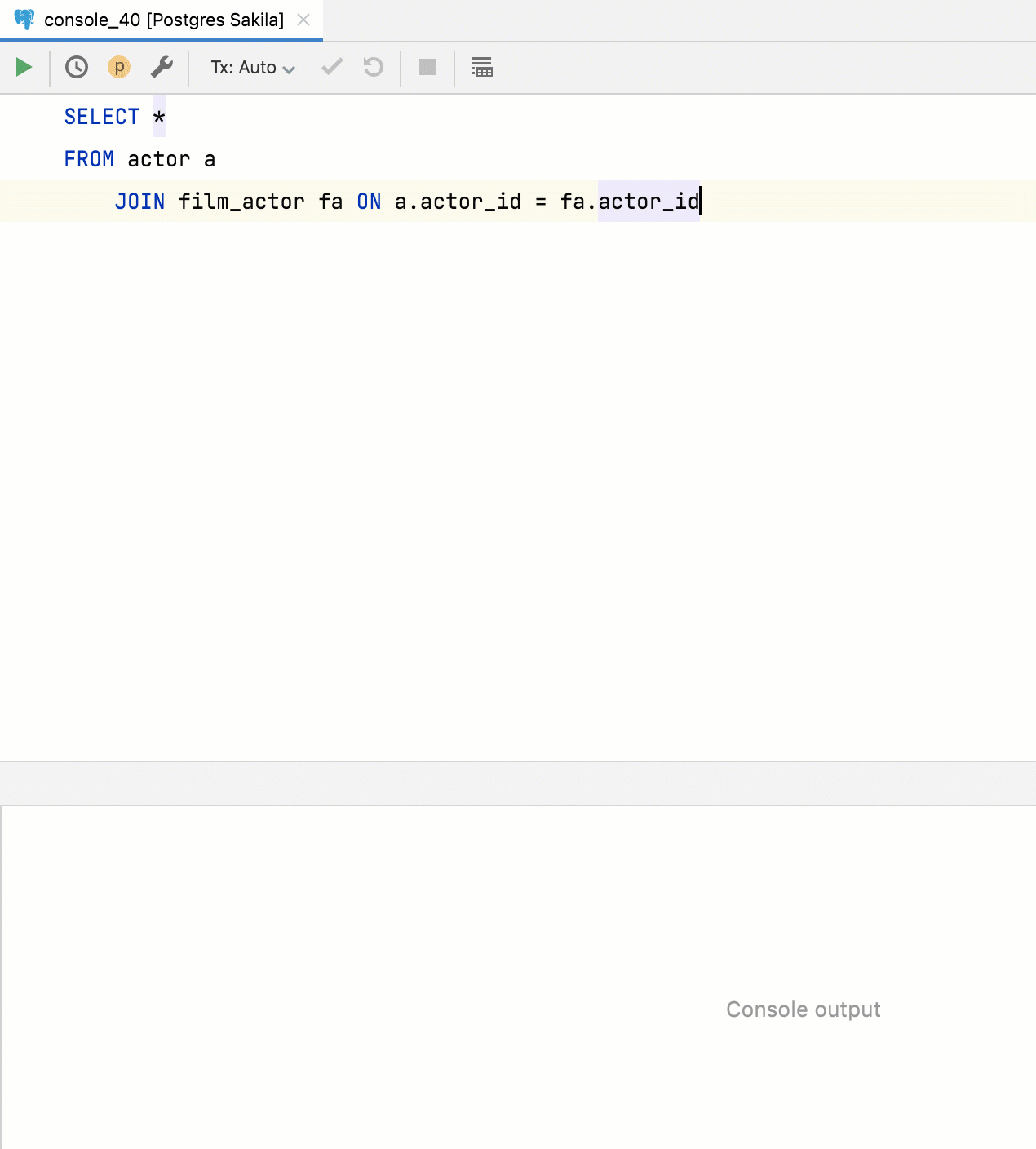 Extract function for queries Now queries can be extracted as a table function. To do this, select the query, invoke the Refactor menu, and use Extract Routine.
Extract function for queries Now queries can be extracted as a table function. To do this, select the query, invoke the Refactor menu, and use Extract Routine.
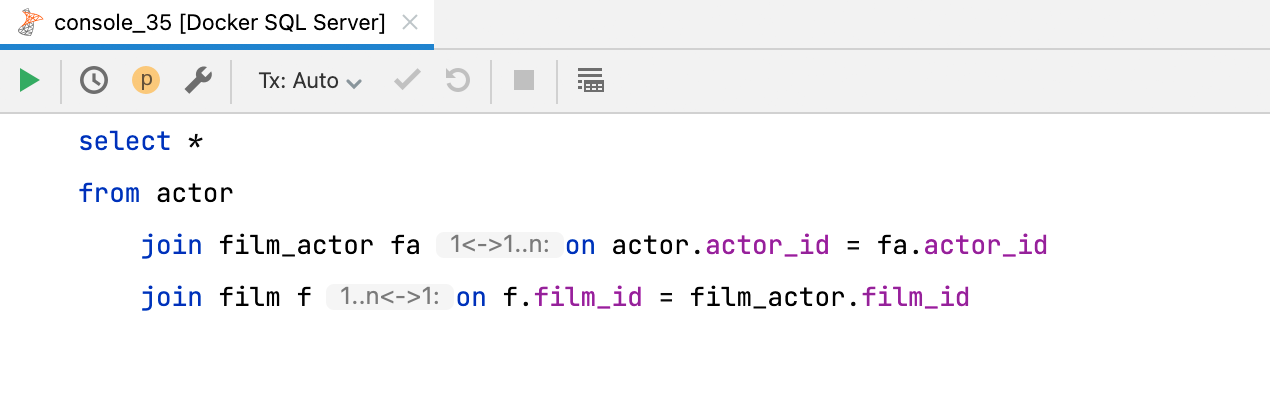 cardinality inlay hint The new inlay hint will tell you the cardinality of a clause. There are three possible options: one-to-one, one-to-many, and many-to-many. If you want to turn it off, you can adjust the setting in Preferences | Editor | Inlay Hints | Join cardinality.
cardinality inlay hint The new inlay hint will tell you the cardinality of a clause. There are three possible options: one-to-one, one-to-many, and many-to-many. If you want to turn it off, you can adjust the setting in Preferences | Editor | Inlay Hints | Join cardinality.
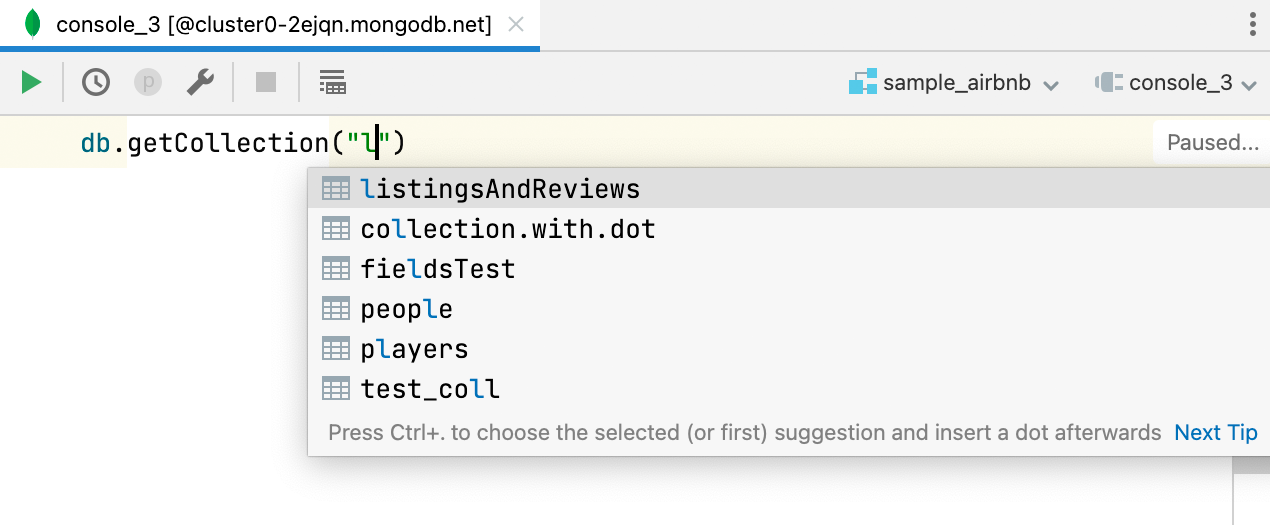 Code completion for database names MongoDB Database names are completed when using , and collection names are completed when using . Additionally, field names are completed and resolved if used from a collection that was defined with . Services tool window
Code completion for database names MongoDB Database names are completed when using , and collection names are completed when using . Additionally, field names are completed and resolved if used from a collection that was defined with . Services tool window
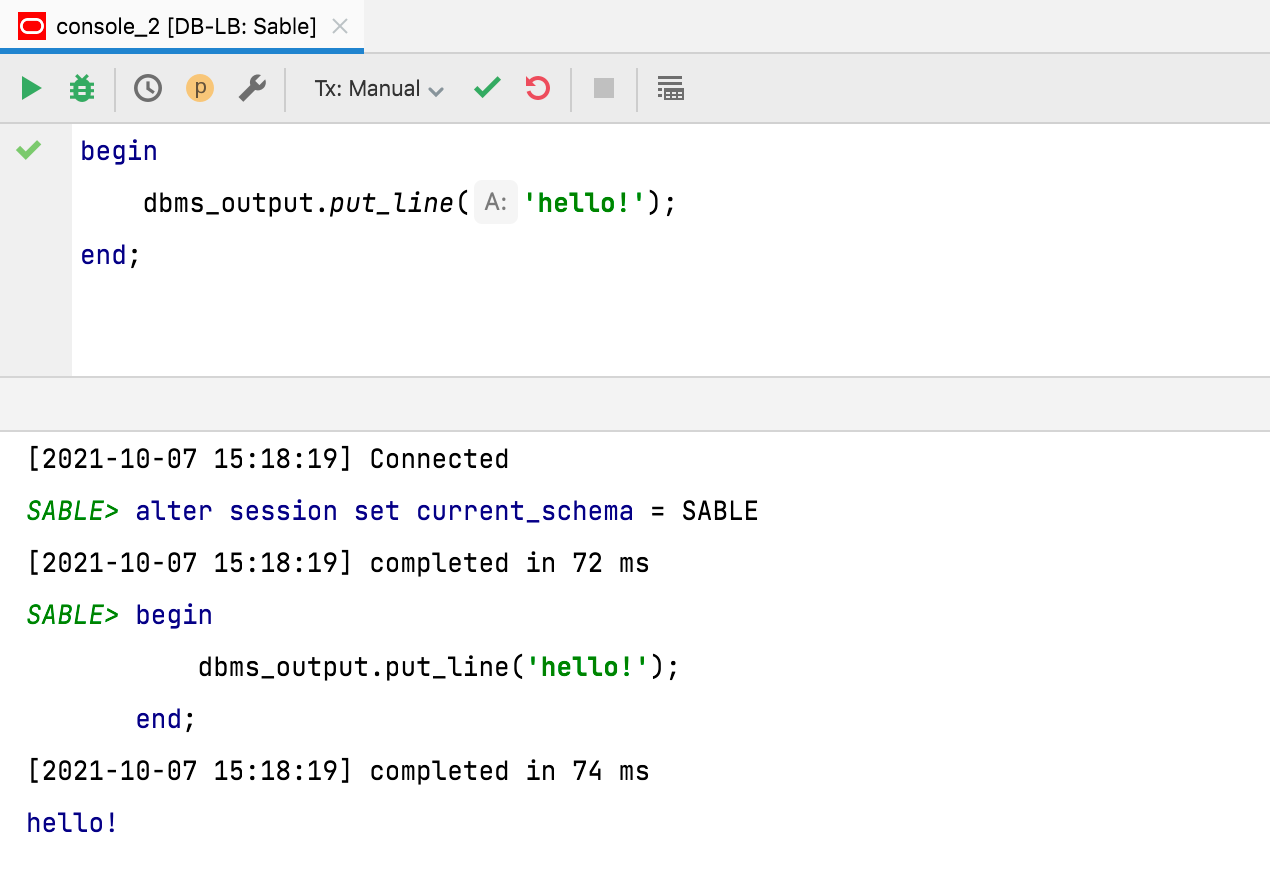 Timestamps in output hidden by default In line with this request, timestamps are no longer shown for query output by default. If you want to return to the previous behavior, you can adjust the setting in Database | General | Show timestamp for query output.
Timestamps in output hidden by default In line with this request, timestamps are no longer shown for query output by default. If you want to return to the previous behavior, you can adjust the setting in Database | General | Show timestamp for query output.
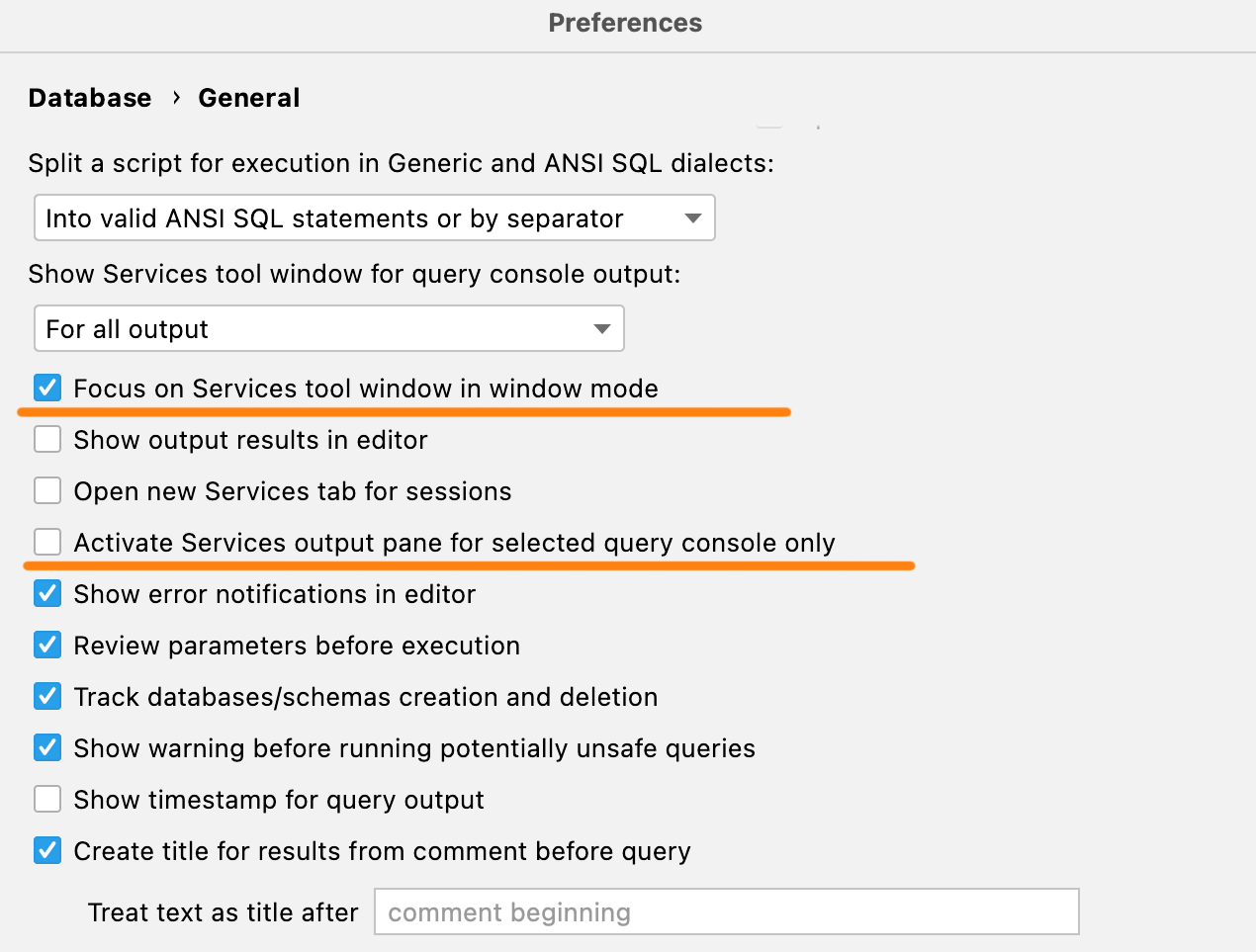 New activation settings If you use the Services tool window in window mode, by default it is hidden behind the IDE. With the new setting you can pass the focus to it every time you run a query, so it will appear after the query has finished. Also, if you are annoyed when finishing a long query in some other console activates the corresponding tab in the Services tool window, select the Activate Services output pane for selected query console only checkbox. Import/Export
New activation settings If you use the Services tool window in window mode, by default it is hidden behind the IDE. With the new setting you can pass the focus to it every time you run a query, so it will appear after the query has finished. Also, if you are annoyed when finishing a long query in some other console activates the corresponding tab in the Services tool window, select the Activate Services output pane for selected query console only checkbox. Import/Export
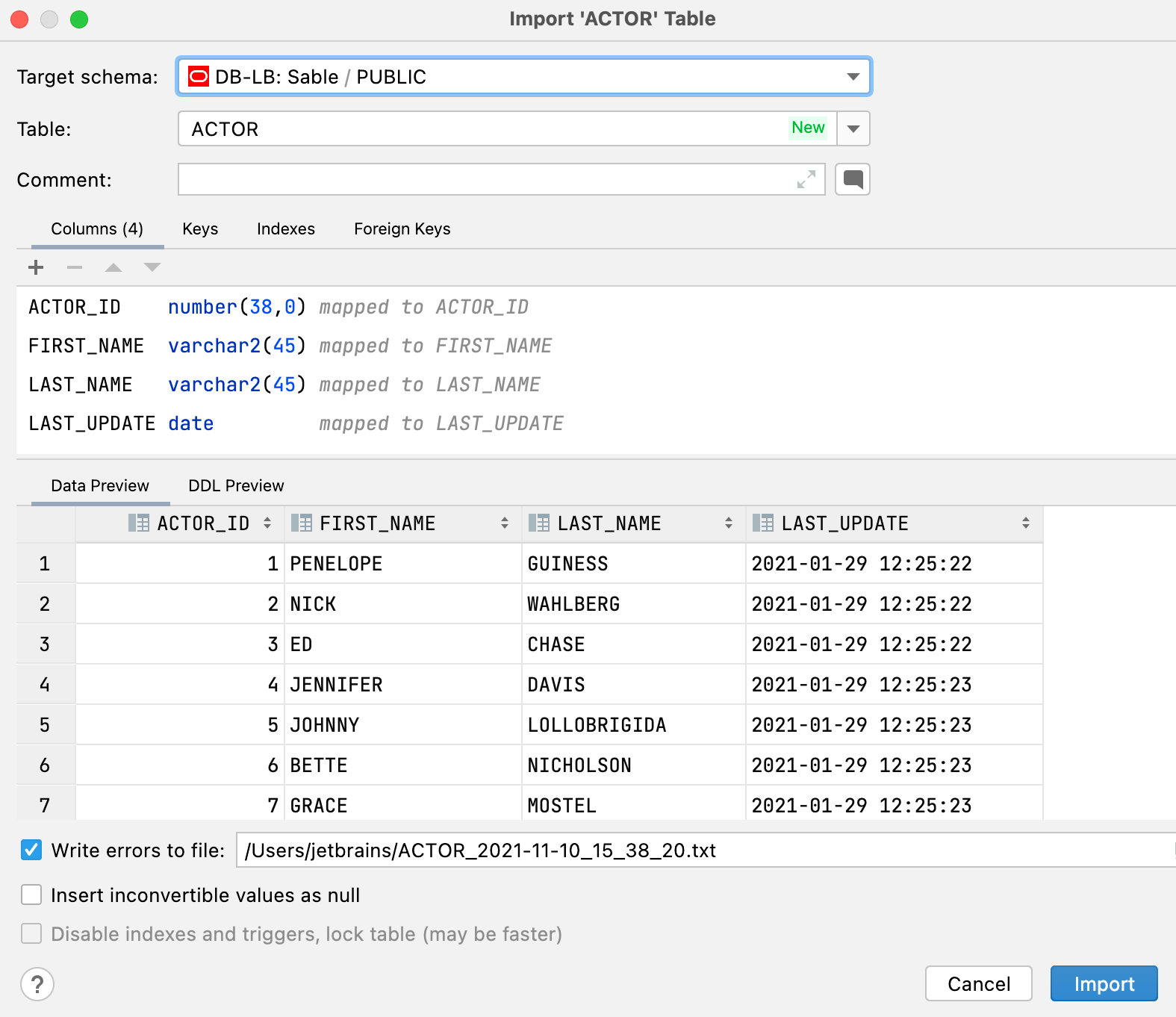 New UI for importing data When importing .csv files or copying tables/result sets, you will observe the following improvements: You can choose an existing table or create a new one. You can change the target schema in the import dialog. The dedicated dialog for the target will not appear if you copy a table or result set. The target is saved as default per schema. So, if you are constantly copying from one particular schema to the other, there will be no need to choose the target each time.
New UI for importing data When importing .csv files or copying tables/result sets, you will observe the following improvements: You can choose an existing table or create a new one. You can change the target schema in the import dialog. The dedicated dialog for the target will not appear if you copy a table or result set. The target is saved as default per schema. So, if you are constantly copying from one particular schema to the other, there will be no need to choose the target each time.
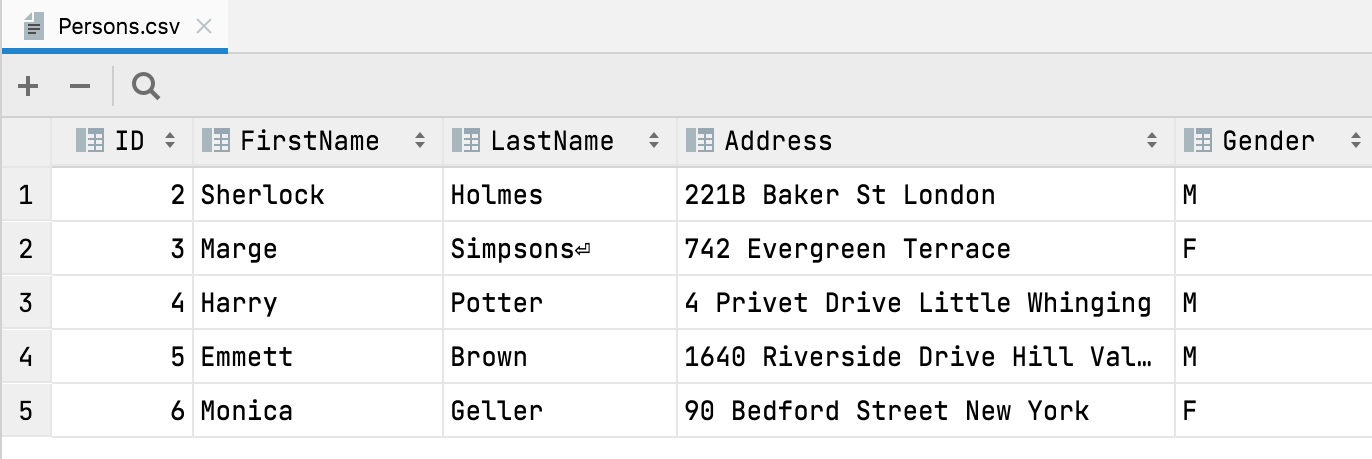 First row is header auto-detection When you open or import a CSV file, DataGrip will now automatically detect that the first row is the header and contains the names of the columns.
First row is header auto-detection When you open or import a CSV file, DataGrip will now automatically detect that the first row is the header and contains the names of the columns.
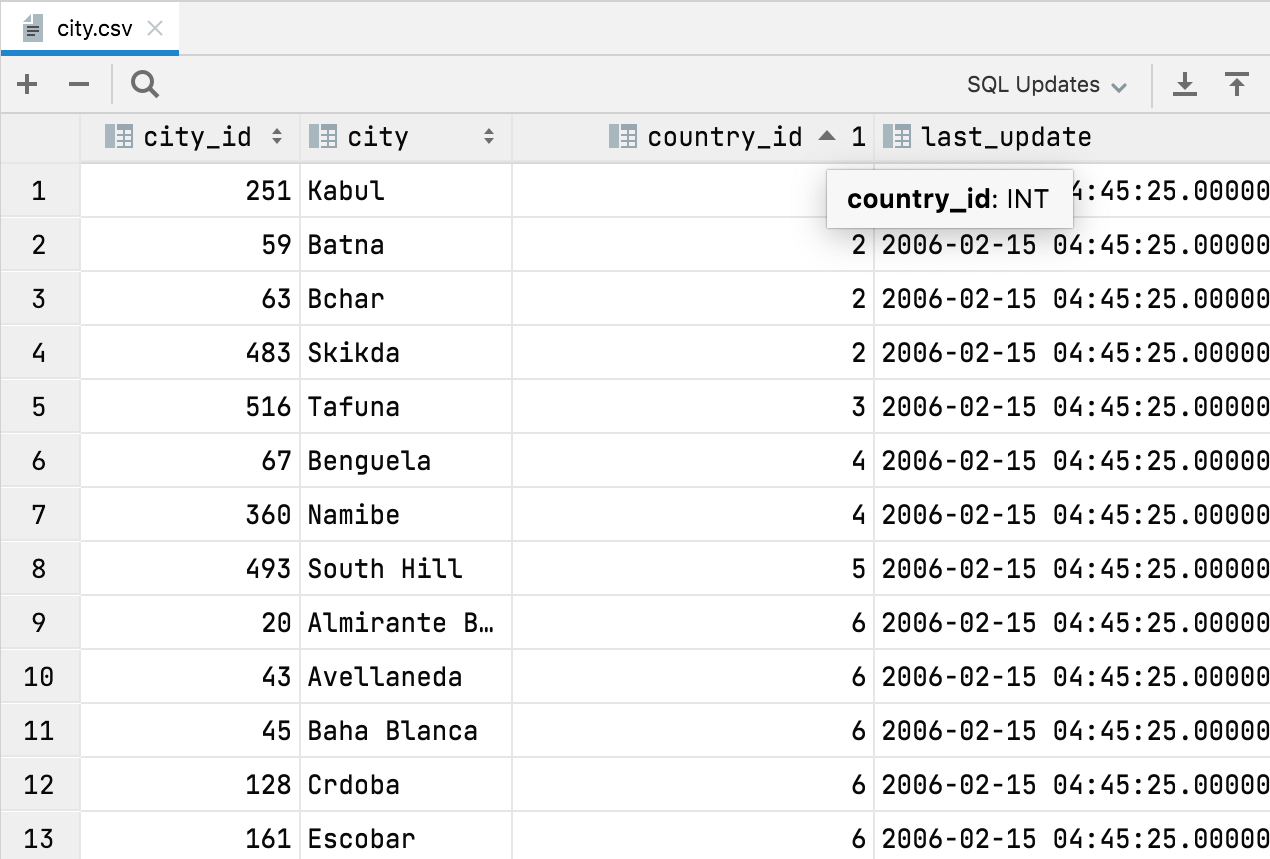 Automatic column types in CSV files DataGrip can now detect column types in CSV files. The main benefit of this is that you can sort data by numeric values. Before, they were treated as text and the sorting wasn’t intuitive. Miscellaneous
Automatic column types in CSV files DataGrip can now detect column types in CSV files. The main benefit of this is that you can sort data by numeric values. Before, they were treated as text and the sorting wasn’t intuitive. Miscellaneous
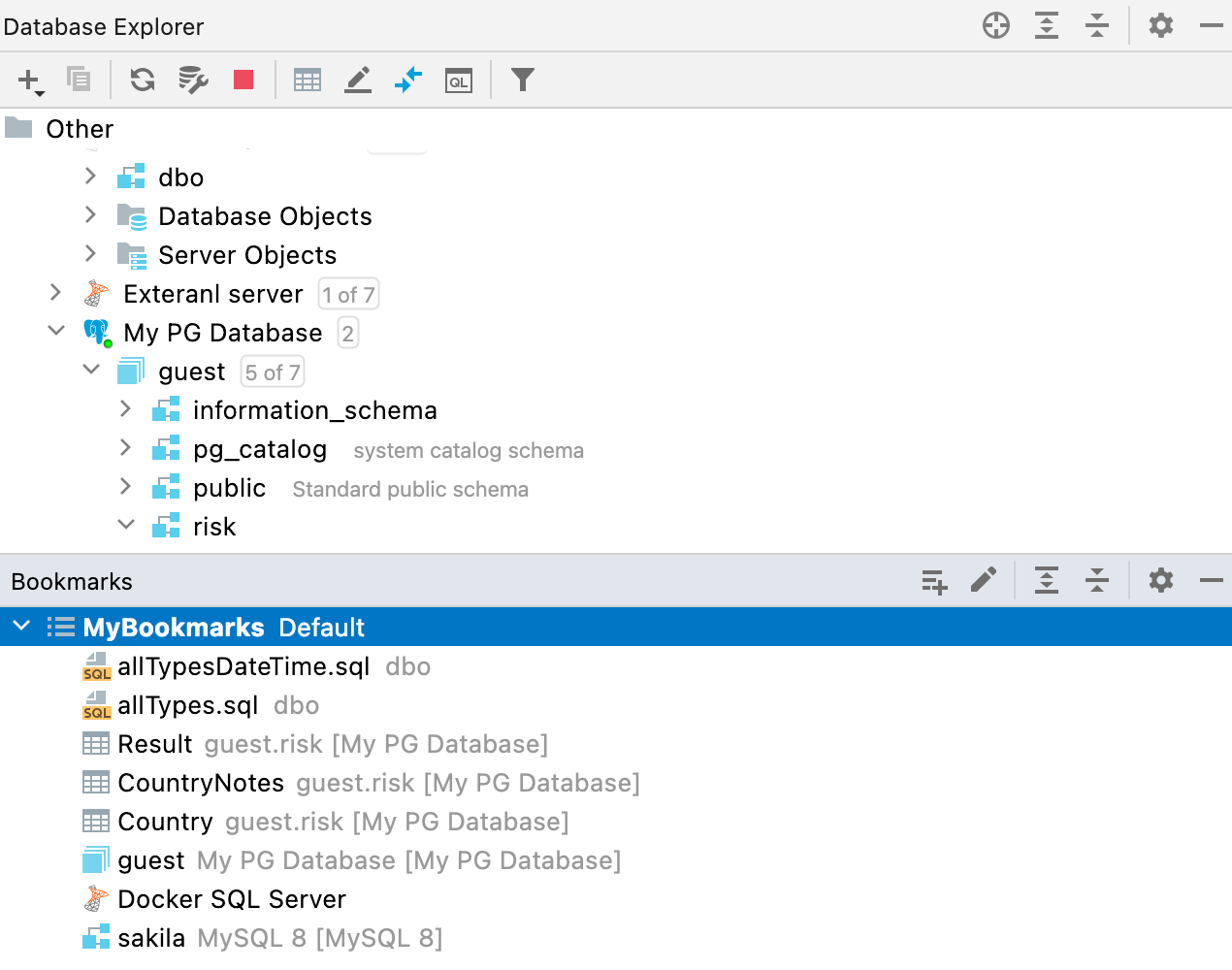 New Bookmarks tool window Before we had two very similar instances – Favorites and Bookmarks. As the difference between the two could sometimes be confusing, we’ve decided to stick to just one – Bookmarks. We’ve reworked the workflow for this functionality and made a new tool window for it. From now on, all the objects or files you mark as important (with the F3 shortcut on macOS or F11 on Windows/Linux) will be located in the new Bookmarks tool window.
New Bookmarks tool window Before we had two very similar instances – Favorites and Bookmarks. As the difference between the two could sometimes be confusing, we’ve decided to stick to just one – Bookmarks. We’ve reworked the workflow for this functionality and made a new tool window for it. From now on, all the objects or files you mark as important (with the F3 shortcut on macOS or F11 on Windows/Linux) will be located in the new Bookmarks tool window.
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://daima100.com/datagrip-ji-huo/8929.html